require(rms)
# Fetch the old lrm.fit (function olrm)
require(orms)
# Define simple timer functions with and without printing
stime <- function(...) {
ti <- system.time(...)['elapsed']
cat('Elapsed time: ', ti, 's\n', sep='')
invisible(ti)
}
stim <- function(...) system.time(...)['elapsed']
# Define a function that will time a series of lines of code, repeating each
# reps times (default is 10). When only one line of code is given, the
# elapsed execution time is printed and the result of the line is returned.
# Otherwise, a vector of run times corresponding to all the lines of code is
# returned, and the values returned from the lines are stored in the global
# environment in object Res, with components named according to inputs to tim.
# When reps > 1 the values from running code lines are from the last rep.
tim <- function(...) {
reps <- 10
w <- sys.call()
n <- names(w)
m <- length(n)
k <- 2 : m
if('reps' %in% n) {
i <- which(n == 'reps')
reps <- eval(w[[i]])
k <- setdiff(k, i)
}
n <- n[k]
m <- length(n)
r <- numeric(m)
Res <<- vector('list', m) # put in global environment
names(r) <- n
names(Res) <<- n
l <- 0
for(i in k) {
l <- l + 1
s <- stim(for(j in 1 : reps)
R <- eval(w[[i]], parent.frame())) / reps
r[l] <- s
Res[[l]] <<- R
}
label(r) <- paste('Per-run execution time in seconds, averaged over', reps, 'runs')
if(m == 1) {
print(r)
return(R)
}
r
}
m <- function(x) max(abs(x))
mad <- function(a, b) c(mad = mean(abs(a - b)),
relmad = 2 * mean(abs(a - b) / (abs(a) + abs(b))))
wratio <- function(r) exp(max(abs(log(r)))) # worst ratio, whether < or > 1.0
# Function creating a table of matrix dimensions for matrices in a list
mdim <- function(w) {
i <- sapply(w, is.matrix)
g <- function(x) c(rows=nrow(x), columns=ncol(x))
sapply(w[i], g)
}
# Function to summarize a series of model fits stored in Res
smod <- function() {
max_abs_u <- sapply(Res, function(x) if(length(x$u)) m(x$u) else NA)
iter <- sapply(Res, function(x) if(length(x$iter)) tail(x$iter, 1) else NA)
deviance <- sapply(Res, function(x) if(length(x$deviance)) tail(x$deviance, 1) else NA)
print(data.frame(deviance, max_abs_u, iter))
l <- length(Res)
n <- names(Res)
if(l > 1) {
for(i in 1 : l) {
r <- Res[[i]]
# See if polr or BFGS
a <- inherits(r, 'polr') || (length(r$opt_method) && r$opt_method=='BFGS')
r$var <- if(inherits(r, 'orm'))
vcov(r, intercepts='all') else if(! a) vcov(r)
if(inherits(r, 'polr'))
r$coefficients <- c(-r$zeta, coef(r))
Res[[i]] <- r
}
cat('\nMaximum |difference in coefficients|,',
'Maximum |relative difference|\n',
'worst ratio of covariance matrices\n\n')
d <- NULL
for(i in 1 : (l-1))
for(j in (i+1) : l) {
ri <- Res[[i]]; rj <- Res[[j]]
comp <- paste(n[i], 'vs.', n[j])
co <- mad(ri$coefficients, rj$coefficients)
w <- data.frame(Comparison = comp,
`Max |difference|` = co[1],
`Max |rel diff|` = co[2],
`Cov ratio` = NA, check.names=FALSE)
if(length(ri$var) && length(rj$var))
w$`Cov ratio` <- wratio(ri$var / rj$var)
d <- rbind(d, w)
}
}
d$`Cov ratio` <- ifelse(is.na(d$`Cov ratio`), '', format(d$`Cov ratio`))
rownames(d) <- NULL
d
}Statistical Computing Approaches to Maximum Likelihood Estimation
computing
data-science
inference
likelihood
ordinal
prediction
r
regression
2024
Maximum likelihood estimation (MLE) is central to estimation and development of predictive models. Outside of linear models and simple estimators, MLE requires trial-and-error iterative algorithms to find the set of parameter values that maximizes the likelihood, i.e., makes the observed data most likely to have been observed under the statistical model. There are many iterative optimization algorithms and R programming paradigms to choose from. There are also many pre-processing steps to consider such as how initial parameter estimates are guessed and whether and how the design matrix of covariates is mean-centered or orthogonalized to remove collinearities. While re-writing the R
rms package logistic regression function lrm I explored several of these issues. Comparisons of execution time in R vs. Fortran are given. Different coding styles in both R and Fortran are also explored. Hopefully some of these explorations will help others who may not have studied MLE optimization and related statistical computing algorithms.
Overview
Maximum likelihood estimation (MLE) is a gold standard estimation procedure in non-Bayesian statistics, and the likelihood function is central to Bayesian statistics (even though it is not maximized in the Bayesian paradigm). MLE may be unpenalized (the standard approach) or various penalty functions such as L1 (lasso, absolute value penalty), and L2 (ridge regression; quadratic) penalties may be added to the log-likelihood to achieve shrinkage (aka regularization). I have been doing MLE my entire career, using mainly a Newton-Raphson algorithm with step-halving to achieve rapid convergence. I never stopped to think about other optimization algorithms, and the R language has a good many excellent algorithms included in the base stats package. There is also an excellent maxLik R package devoted to MLE (not used here), and two of its vignettes provide excellent introductions to MLE. General MLE background and methods including more about penalization may be found here, which includes details about how to do QR factorization and to back-transform after the fit.
If you think that ROC area or classification accuracy are good objective functions/optimality criteria, please think again.
In this article I’ll explore several optimization strategies and variations of them, in the context of binary and ordinal logistic regression. The programming scheme that is used here is the one used by many R packages: Write functions to compute the scaler objective function (here, -2 log likelihood), the gradient vector (vector of first derivatives), and the hessian matrix (matrix of second derivatives), and pass those functions to general optimization functions. Convergence (at least to local minima for -2 LL (log of the likelihood function)) is achieved for smooth likelihood functions when the gradient vector values are all within a small tolerance (say \(10^{-7}\)) of zero or when the -2 LL objective function completely settles down in, say, the \(8^\text{th}\) significant digit. The gradient vector is all zeros if the parameter values are exactly the MLEs (local minima achieved on -2 LL).
A different strategy is to use the Bayesian system Stan by specifying LL and letting Stan analytically compute the gradient, then using the Stan optimizer to compute MLEs. If you specify priors, the optimizer provides penalized MLEs. The likelihood function is the bridge between Bayesian and frequentist methods.
This article is based on rms version 7.0-0, a major new release of the package, which will likely be available on CRAN around 2025-01-08.
History
The R rms package lrm function is dedicated to maximum likelihood estimation (MLE) for fitting binary and ordinal (proportional odds) logistic regression models using the logit link, with or without quadratic (ridge) penalization. Semiparamteric regression models, also called ordinal regression models, allow one to do efficient analyses without depending on how the dependent variable Y is transformed. Ordinal models encode the entire cumulative distribution function of Y by having an intercept for each distinct Y level less one. For ordinal models, versions of lrm before rms 6.9-0 were efficient for up to 400 distinct Y-values (399 intercepts) in the sense that execution time was under 10 seconds for 10,000 observations on 10 predictors. The rms orm function is intended for modeling continuous outcome Y variables and was efficient for up to 8000 intercepts prior to rms 7.0-0. orm implements 4 link functions other than the logit. For rms 7.0-0, lrm and orm run in 2.5s for a sample size of 300,000 with continuous Y and 20 predictors, i.e., with 299,999 intercepts (9.5s for 40 predictors). lrm uses the R function lrm.fit for its heavy lifting, and likewise orm uses orm.fit. Much of lrm.fit was written in 1980 and served as the computational engine for the first SAS procedure for logistic regression, PROC LOGIST. It used Fortran 77 for computationally intensive work, and used only a Newton-Raphson algorithm with step-halving for iterative MLE. On rare occasions when serious collinearities were present, such as when multiple continuous variables were fitted using restricted cubic splines (which use a truncated power basis), lrm.fit would fail to converge.
Are Intercepts Regular Parameters?
Let \(F\) be a smooth cumulative distribution function. The cumulative probability class of ordinal semiparametric models can be written as follows. It is more traditional to state the model in terms of \(P(Y \leq y | X)\) but we use \(P(Y \geq y | X)\) so that higher predicted values are associated with higher \(Y\), and when \(F\) is the logistic distribution \(\frac{1}{1 + \exp(-x)}\) the ordinal logistic (proportional odds) model reduces exactly to a binary logistic model. Let the ordered distinct values of \(Y\) be denoted by \(y_{1}, y_{2}, \dots, y_{k}\) and let the \(k\) intercepts associated with \(y_{1}, \dots, y_{k}\) be \(\alpha_{1}, \alpha_{2}, \dots, \alpha_{k}\), where \(\alpha_{1} = \infty\) because \(P(Y \geq y_{1}) = 1\). Let \(\alpha_{y} = \alpha_{i}, i:y_{i}=y\). Then the cumulative probability semiparametric model is
\[ P(Y \geq y | X) = F(\alpha_{y} + X\beta) \]
When \(F\) is the extreme value type I (also called the Gumbel minimum value) distribution \(F(x) = \exp(-\exp(-x))\), the inverse function is the \(\log-\log\) link and the model is a proportional hazards (PH) model. The Cox 1972 PH model uses the only generating distribution \(F(x)\) such that the marginal (getting rid of the \(\alpha\)s) distribution of the ranks of \(Y\) can be evaluated without multi-dimensional integrals. This gives rise to Cox’s partial likelihood, which until time-dependent covariates are included can be computationally fast for any number of distinct failure times. The Cox approach requires a second step to estimate the intercepts (underlying survival curve for a person with some reference value of \(X\beta\)). There is some arbitrariness to which second-step estimator is used, e.g., the Breslow estimator or the Kalbfleisch-Prentice estimator. And variances of \(\hat{P}(Y \geq y | X)\) are complicated because uncertainties from both of the steps must be included.
In fact, a partial likelihood, which also makes it difficult to handle interval censoring, is only needed until you realize that
- the maximum likelihood estimate (MLE) of the vector of intercepts \(\alpha\) when \(\beta=0\) are just the link function of all the one minus cumulative probabilities in the absence of censoring; this gives rise to instantly-computed and convergence-accelerating initial values for iterative MLE estimation
- the \(\alpha\)s are always in descending order (ascending if using the more popular statement of ordinal models)
- the gradient (first derivative) for the log likelihood function can be computed quickly no matter how large is \(k\)
- the hessian (second derivatives of the log likelihood function) can be computed in just over twice the time needed to compute the gradient, and takes twice the amount of array storage size as the gradient, so MLE scales wonderfully for large \(k\)
- for most needs, the entire information matrix (negative hessian) never needs to be inverted; portions of the inverse of the whole can be quickly computed without inverting the whole information matrix
- the R
Matrixpackage is made for efficient storage and calculation on such sparse hessians
Twice because the intercept portion of the hessian is tri-band diagonal and one only needs to store the diagonal and above-diagonal elements due to symmetry.
Because of the strict ordering of \(\alpha\), MLE iterations are fast and the effective degrees of freedom of the model are more like \(4 + p\) where \(p\) is the number of \(\beta\)s. The \(4\) comes from the following line of reasoning. In the no-covariate case, consider confidence bands for the empirical cumulative distribution function (ECDF) for \(Y\) , then fit a 4-parameter parametric distribution to the raw \(Y\) values. Confidence intervals for \(F(y)\) from this parametric fit will be about the same widths as those from the ECDF.
ECDF = \(F(\alpha)\) when \(\beta=0\)This exercise would also point out the lack of value in fitting flexible parametric distributions compared to generalizing the ECDF to handle covariates by using a semiparametric model.
Re-Write of lrm.fit and orm.fit
To modernize the Fortran code, better condition the design matrix \(X_{n\times p}\) (\(n\) observations and \(p\) columns), and to explore a variety of optimization algorithms, I did a complete re-write of the rms package lrm and lrm.fit functions in November, 2024, for rms version 6.9-0. To reduce optimization divergence when there are extreme collinearities, and to better scale \(X\), I was interested in implementing mean centering followed by a QR factorization of \(X\) to orthogonalize its columns. Details about how this is done and how the parameter estimates and covariance matrix are converted back to the original \(X\) space may be found here. QR can be turned on by setting the lrm.fit argument transx to TRUE. When QR is in play, the rotated columns of \(X\) are scaled to have standard deviation 1.0.
Besides dealing with fundamental statistical computing issues, I changed lrm.fit to use Therneau’s survival package concordancefit function to compute concordance probabilities used by various rank correlation indexes such as Somers’ \(D_{xy}\). This got rid of a good deal of code. Previously, lrm.fit binned predicted probabilities into 501 bins to calculate rank measures almost instantly. But I decided it was time to use exact calculations now that concordancefit is so fast. Though not used in rms, concordancefit also computes accurate standard errors.
A new Fortran 2018 subroutine lrmll was written to efficiently calculate the -2 log-likelihood function (the deviance), the gradient vector, and the hessian matrix of all second partial derivatives of the log-likelihood with respect to intercept(s) \(\alpha\) and regression coefficients (slopes) \(\beta\).
lrm.fit now implements several optimization algorithms. When Y is binary and there is no penalization, it has the option to use glm.fit(..., family=binomial()) which runs iteratively reweighted least squares, a fast-converging algorithm for binary logistic regression (but does not extend to ordinal regression). lrm.fit implements 8 optimization algorithms.
- optional for proportional odds models (according to
lrm.fitinitglmargument), does a first pass withglm.fitthat fits a binary logistic regression for the probability that Y is greater than or equal to the median Y; this fit can then be used for starting values after shifting the default starting intercept values so that the middle intercept matches the intercept from the binary fit nlminb: a function in thestatspackage, tied withNRas the fastest algorithm in general; uses hessians. This uses Fortran routines in the Bell Labs port library for which the original paper may be found here.NR: Newton-Raphson iteration with step-halving, implemented here as R functionnewtonr. This algorithm is the default because it has the advantage of having full control over convergence criteria. It requires convergence with respect to 3 simultaneous criteria: changes in -2 LL, changes in parameter estimates, and nearness of gradient to zero. The user can relax any of the 3 criteria thresholds to relax conditions. This is the optimization method used in the oldlrm.fitfunction, but written in Fortran there for slightly increased speed. Defaults for tolerance parameters are such thateps(iteration-to-iteration change in -2 LL) will usually dictate when convergence called.LM: Levenberg-Marquart algorithm, which is a kind of Newton method with generalized step-halvingglm.fit: for binary Y without penalization onlynlm: thestatsfunction that is usually recommended for maximum likelihood, but I found it is slower thannlminbwithout offering other advantagesBFGSandL-BFGS-Busing thestatsoptimfunction: fast general-purpose algorithms that do not require the hessian, so these can be used with an unlimited number of intercepts as long as the user sets thelrm.fitparametercompvartoFALSEso that the hessian is not calculated once after convergenceCGandNelder-Mead: seeoptim
This was inspired by the
MASS package polr functionThe last four methods do not involve computing the hessian, which is the most computationally intensive calculation in MLE. But they are still slower overall if you want to get absolute convergence, due to requiring many more evaluations of the object function (-2 LL).
See this for useful comparisons of some of the algorithms.
For rms 7.0-0, lrm.fit and orm.fit were changed to use the R Matrix package for much more efficient handling of sparse Hession/information matrices. Now there are no limitations on the number of distinct Y-values analyzed by lrm and orm. The primary differences between the two modeling procedures are
lrmonly implements a single link function (logistic)lrmimplements multiple optimization methodsormonly implements Newton-Raphson optimization (with step-halving) and Levenberg-Marquardtlrmoutput (fromprint.lrm) includes rank correlation model performance indexes that are more suitable for discrete Yormoutput (fromprint.orm) includes only Spearman’s \(\rho\) as a rank predictive discrimination measure; this is more suitable for continuous Yormhas aQuantileand anExProbmethod; bothlrmandormhaveMeanmethods, as means work on discrete numeric Y (unlike quantiles)lrmimplementstransxforQRorthonormalization of the design matrix \(X\)ormimplementsscalefor mean-centering and standard deviation scaling of \(X\)
Background: Convergence
The two most commonly used convergence criteria for MLE are
- relative convergence: stop iterations when the change in deviance is small or when the relative change in parameter estimates is small
- absolute convergence: stop iterations when the first derivative of the log likelihood is small in absolute value for all parameters, or there is a very small absolute change in parameter values
Absolute convergence with respect to the first derivatives (gradients) is similar to demanding that none of the regression parameters change very much since the last iteration. From the standpoint of what is important statistically, convergence of the deviance (what the gold standard likelihood ratio test is based on) is sufficient with respect to what matters. Changing parameter values when the deviance does not change in the \(6^\text{th}\) decimal place will be buried in the noise. Absolute convergence may affect \(\hat{\beta}\), but relative convergence tends to result in a very stable \(\frac{\hat{\beta}}{\text{s.e.}}\). You might deem convergence satisfactory when parameter estimates between successive iterations change by less than 0.05 standard errors (which would require evaluation of the hessian to know), but approximately this corresponds to relative convergence judged by the deviance.
Despite achieving statistically relevant convergence more easily, there is a real issue of reproducibility. Different algorithms and software may result in semi-meaningful differences in \(\hat{\beta}\) taken in isolation (ignoring how much of \(\hat{\beta}\) is noise). Only by having all the implementations achieve absolute convergence will different analysts be very likely to reproduce each others’ work. If this is important to you, either avoid the BFGS algorithms (for which the R optim function does not have an absolute convergence criterion) or use a highly stringent relative convergence criterion, e.g., specify the lrm.fit argument reltol as \(10^{-11}\). Below I explore how convergence and execution time are affected by reltol.
Overview of Findings
opt_method='NR' and 'nlminb' are the fastest methods, even slightly faster than glm.fit.
Limited tests of transx in lrm.fit to use QR factorization does not show not much benefit, but see below for details.
For ordinal Y, using opt_method='BFGS' with compstats=FALSE for lrm mimics the polr function in the MASS package. For a large number of intercepts, lrm.fit is much faster due to computing the deviance and derivatives in highly efficient compiled Fortran and capitalizing on sparse matrices.
Setting initglm=TRUE tells lrm.fit to get initial ordinal model parameter values from a binary logistic glm.fit run when cutting Y at the median. This does not seem to offer much benefit over setting starting values to covariate-less MLEs of \(\alpha\) (which are calculated instantly when \(\beta=0\)) and setting \(\beta=0\). In one example using nlminb the algorithm actually diverged with initglm=TRUE but ran fine without it. This is probably due to large intercept values with many distinct Y values.
Extensive tests of opt_method='BFGS' show good stochastic performance (convergence to what matters, deviance-wise), but unimpressive execution time if you want absolute convergence by setting reltol to a small number.
The best overall algorithm that uses the hessian is NR in terms of speed and convergence, with nlminb and LM close seconds. NR is the method used in the old lrm.fit, so for most datasets, the new optimization options are not needed.
Even though lrm.fit is optimized for the logistic link function, there is not much difference in execution time between lrm.fit and orm.fit for binary and ordinal logistic models.
Validation
Two kinds of validations appear below.
- Validation of the Fortran-calculated deviance and derivatives: for a given small dataset, get parameter estimates from
rms::ormwith tight convergence criteria, and test the Fortran code by evaluating the deviance and derivatives at these parameter values. The gradient (first derivative) should be very close to zero, and the deviance should be identical to that fromorm. The inverse of the negative of the hessian matrix should equal the variance-covariance matrix computed byorm. - Validate
lrm.fitoverall by letting it pick its usual starting values for iteration, and compare its output to that fromormand other fitting functions including the last pre-6.9-0 version oflrm.fitwhich is namedolrmbelow.
Check -2 Log Likelihood and Derivatives for a Simple Model
First define an R function that makes it easy to run the Fortran subroutine.
rfort <- function(x, y, alpha, beta, what=2L, debug=0L, penhess=1L,
offset=rep(0., n), wt=rep(1., n),
penmat=matrix(0., p, p)) {
x <- as.matrix(x)
p <- ncol(x)
n <- nrow(x)
yd <- sort(unique(y))
k <- max(yd)
nv <- as.integer(k + p)
if(length(yd) != k + 1 || any(yd != 0 : k))
stop('y must be coded 0-k for lrmll')
storage.mode(x) <- storage.mode(offset) <- storage.mode(wt) <- storage.mode(penmat) <-
storage.mode(alpha) <- storage.mode(beta) <- 'double'
w <- .Fortran('lrmll', n, as.integer(k), p, x, as.integer(y),
offset, wt, penmat, alpha, beta,
logL=numeric(1), grad=numeric(nv),
a=matrix(0e0, k, 2), b=matrix(0e0, p, p), ab=matrix(0e0, k, p),
what=as.integer(what), debug=as.integer(debug),
penhess=as.integer(penhess), salloc=integer(1))
# lrmll creates 3 compact hessian submatrices
# Put them together into a single hessian
w$hess <- infoMxop(w[c('a', 'b', 'ab')])
w
}Binary Y
x <- 1 : 10
y <- c(0, 1, 0, 0, 0, 1, 0, 1, 1, 1)
# From orm. Deviance = 13.86294, 10.86673
alpha <- -2.4412879506377 ; beta <- 0.4438705364796
w <- rfort(x, y, alpha, beta)
w$logL[1] 10.86673w$grad[1] -1.814104e-13 -1.156408e-12w <- rfort(x, y, alpha, beta, what=3L)
w$hess # negative inverse of covariance matrix [,1] [,2]
[1,] -1.813852 -9.976185
[2,] -9.976185 -66.123262- solve(vcov(glm(y ~x, family=binomial(), control=list(epsilon=1e-12)))) (Intercept) x
(Intercept) -1.813852 -9.976185
x -9.976185 -66.123262Res <- list(glm = glm(y ~ x, family=binomial(), control=list(epsilon=1e-12)),
olrm = olrm(x, y, eps=1e-10),
lrm.fit = lrm.fit(x, y, reltol=1e-12),
orm = orm(y ~ x, eps=1e-10) )
smod() deviance max_abs_u iter
glm 10.86673 NA 4
olrm 10.86673 2.220446e-15 NA
lrm.fit 10.86673 3.270271e-08 5
orm 10.86673 8.326673e-17 5
Maximum |difference in coefficients|, Maximum |relative difference|
worst ratio of covariance matrices Comparison Max |difference| Max |rel diff| Cov ratio
1 glm vs. olrm 5.551115e-16 4.320309e-16 1
2 glm vs. lrm.fit 5.551115e-16 4.320309e-16 1
3 glm vs. orm 5.273559e-16 3.695001e-16 1
4 olrm vs. lrm.fit 0.000000e+00 0.000000e+00 1
5 olrm vs. orm 2.775558e-17 6.253079e-17 1
6 lrm.fit vs. orm 2.775558e-17 6.253079e-17 1Cov ratio in the above output is the anti-log of the absolute value of the log of the ratio of elements of two covariance matrices. So it represents the worst disagreement in the two matrices, with 1.0 being perfect agreement to 7 decimal places. Max |difference| is the highest absolute difference in estimated regression coefficients between two methods, and Max |rel diff| is the maximum ratio of absolute differences to the sum of absolute values of two coefficient estimates.Y=0, 1, 2
x <- 1 : 10
y <- c(0, 2, 0, 1, 0, 2, 2, 1, 1, 2)
f <- orm(y ~ x, eps=1e-10) # deviance 21.77800 19.79933
- solve(vcov(f, intercepts='all')) y>=1 y>=2 x
y>=1 -2.336337 1.148893 -5.103426
y>=2 1.148893 -2.657167 -10.455125
x -5.103426 -10.455125 -110.128337- solve(vcov(lrm(y ~ x, eps=1e-10))) y>=1 y>=2 x
y>=1 -2.336337 1.148893 -5.103426
y>=2 1.148893 -2.657167 -10.455125
x -5.103426 -10.455125 -110.128337- solve(olrm(x, y, eps=1e-10)$var) y>=1 y>=2 x[1]
y>=1 -2.336337 1.148893 -5.103426
y>=2 1.148893 -2.657167 -10.455125
x[1] -5.103426 -10.455125 -110.128337- solve(vcov(MASS::polr(factor(y) ~ x))) x 0|1 1|2
x -110.12802 5.103400 10.455131
0|1 5.10340 -2.336318 1.148877
1|2 10.45513 1.148877 -2.657156# Note a problem with VGAM
- solve(vcov(VGAM::vglm(y ~ x, VGAM::cumulative(reverse=TRUE, parallel=TRUE)))) (Intercept):1 (Intercept):2 x
(Intercept):1 -2.434082 1.155134 -5.148614
(Intercept):2 1.155134 -2.580855 -9.505256
x -5.148614 -9.505256 -100.063658- solve(vcov(ordinal::clm(factor(y) ~ x))) 0|1 1|2 x
0|1 -2.336337 1.148893 5.103426
1|2 1.148893 -2.657167 10.455125
x 5.103426 10.455125 -110.128337alpha <- c(-0.8263498291155, -2.3040967379853)
beta <- 0.3091154153068
# Analytically compute 2nd derivative of log L wrt beta
info <- function(x) {
p1 <- plogis(alpha[1] + x * beta)
p2 <- plogis(alpha[2] + x * beta)
d <- p1 - p2
v1 <- p1 * (1 - p1)
v2 <- p2 * (1 - p2)
v1 - v2
w1 <- p1 * (1 - p1) * (1 - 2 * p1)
w2 <- p2 * (1 - p2) * (1 - 2 * p2)
w1 - w2
x * x * ((w1 - w2) * d - (v1 - v2)^2) / d / d
}
# Compute 2nd derivative of log(p1 - p2) wrt beta numerically
dif <- function(x, beta) log(plogis(alpha[1] + x * beta) - plogis(alpha[2] + x * beta))
del = 1e-6
d2 <- function(x) ((dif(x, beta + del) - dif(x, beta)) / del - (dif(x, beta) - dif(x, beta - del)) / del) / del
c(info(4), info(8), info(9))[1] -6.88269 -24.55641 -27.93077num <- c(d2(4), d2(8), d2(9))
print(num)[1] -6.882495 -24.556135 -27.931213sum(num)[1] -59.36984w <- rfort(x, y, alpha, beta)
w$logL[1] 19.79933w$grad[1] -1.896261e-13 -1.408873e-13 -2.330580e-12w <- rfort(x, y, alpha, beta, what=3L)
w$hess3 x 3 sparse Matrix of class "dgCMatrix"
[1,] -2.336337 1.148893 -5.103426
[2,] 1.148893 -2.657167 -10.455125
[3,] -5.103426 -10.455125 -110.128337Simple Ordinal Model With Weights, Offsets, and Penalties
We first ignore weights, offsets, and penalties, then incorporate them.
set.seed(1)
x1 <- rnorm(50)
x2 <- rnorm(50)
X <- cbind(x1, x2)
y <- sample(0:5, 50, TRUE)
wt <- runif(50)
wt <- wt / sum(wt)
of <- rnorm(50)
pm <- cbind(c(1.2, 0.6), c(0.6, 1.2))
f <- olrm(X, y, eps=1e-15)
f$deviance[1] 177.1350 176.8656cof <- coef(f)
w <- rfort(X, y, cof[1:5], cof[6:7])
w$logL[1] 176.8656w$grad[1] 4.160439e-11 1.768230e-11 -4.204526e-11 -7.764234e-12 -3.765321e-13
[6] -1.289524e-12 7.128742e-13w <- rfort(X, y, cof[1:5], cof[6:7], what=3L)
range(w$hess + solve(vcov(f)))[1] -58.68270 51.98111# Needed reltol=1e-15 to get gradient to 1e-8 with BFGS
# CG achieved 1e-6 with default, with 475 function evaluations
g <- lrm.fit(X, y, trace=1, opt_method='nlm', gradtol=1e-14,
transx=TRUE, compstats=FALSE)iteration = 0
Step:
[1] 0 0 0 0 0 0 0
Parameter:
[1] 1.51634749 0.57536414 -0.08004271 -0.84729786 -2.19722458 0.00000000
[7] 0.00000000
Function Value
[1] 177.135
Gradient:
[1] 1.199041e-14 -2.664535e-15 -1.243450e-14 7.993606e-15 3.330669e-15
[6] 2.510851e+00 3.400018e+00
iteration = 4
Parameter:
[1] 1.53972787 0.60066749 -0.06107634 -0.83760533 -2.19876783 -0.07124309
[7] -0.10606549
Function Value
[1] 176.8656
Gradient:
[1] -8.387024e-11 -3.563017e-11 8.474110e-11 1.566214e-11 7.490675e-13
[6] 5.339063e-12 9.486856e-13
Last global step failed to locate a point lower than x.
Either x is an approximate local minimum of the function,
the function is too non-linear for this algorithm,
or steptol is too large.m(g$u); g$iter # L-BFGS-B tool factor as low as 1e2 to get u=3e-6, 50 iter[1] 4.237055e-11[1] 4mad(cof, g$coefficients) mad relmad
1.066508e-14 3.650349e-14 range(f$var / vcov(g))[1] -95.44248 25.29241Now use weights, offset, and penalties.
f <- olrm(X, y, offset=of, weights=wt, penalty.matrix=2*pm, eps=1e-12)
f$deviance[1] 3.475801 3.803296 3.799336cof <- coef(f)
w <- rfort(X, y, cof[1:5], cof[6:7], offset=of, wt=wt, penmat=2*pm)
w$logL[1] 3.799336w$grad[1] 4.683753e-17 -9.714451e-17 -5.204170e-18 3.469447e-18 -3.903128e-17
[6] -3.469447e-18 0.000000e+00w <- rfort(X, y, cof[1:5], cof[6:7], offset=of, wt=wt, penmat=2*pm, what=3L)
range(w$hess + solve(vcov(f)))[1] -1.776357e-15 1.332268e-15g <- lrm.fit(X, y, trace=3, offset=of, weights=wt,
penalty.matrix=2e0*pm, opt_method='nlminb', compstats=FALSE) 0: 3.8301785: 1.23911 0.611204 -0.0435624 -0.772679 -2.45652
3: 3.8032957: 1.50965 0.925273 0.280639 -0.513375 -2.39790
0: 3.8032957: 1.50965 0.925273 0.280639 -0.513375 -2.39790 0.00000 0.00000
3: 3.7993356: 1.50984 0.927634 0.283085 -0.513316 -2.39750 0.0149656 -0.0431891m(g$u); g$iter[1] 3.404934e-09 iterations evaluations.function evaluations.gradient
3 4 3 mad(coef(f), coef(g)) mad relmad
7.703453e-09 7.127106e-09 g$iter iterations evaluations.function evaluations.gradient
3 4 3 g$u y>=1 y>=2 y>=3 y>=4 y>=5
3.404934e-09 6.040723e-10 -1.193834e-09 -1.123210e-09 -1.671228e-09
x1 x2
3.391934e-10 7.970917e-11 f$deviance[1] 3.475801 3.803296 3.799336g$deviance[1] 3.475801 3.803296 3.799336range(vcov(f) / vcov(g))[1] 0.9999999 1.0000002Check Accuracy Against Old lrm.fit For a Variety of Levels of Y
set.seed(1)
n <- 150
w <- NULL
for(i in 1 : 40) {
k <- sample(1 : 20, 1, TRUE)
y <- sample(0 : k, n, TRUE)
x1 <- runif(n)
x2 <- exp(rnorm(n))
X <- cbind(x1, x2)
f <- olrm(X, y, eps=1e-10)
g <- lrm.fit( X, y, opt_method='nlminb', compstats=FALSE)
d <- coef(f) - coef(g)
r <- wratio(vcov(f) / vcov(g))
w <- rbind(w, data.frame(i, k, mad.beta=m(d), Cov.ratio=r))
}
range(w$Cov.ratio)[1] 1 1with(w, plot(k, mad.beta, log='y'))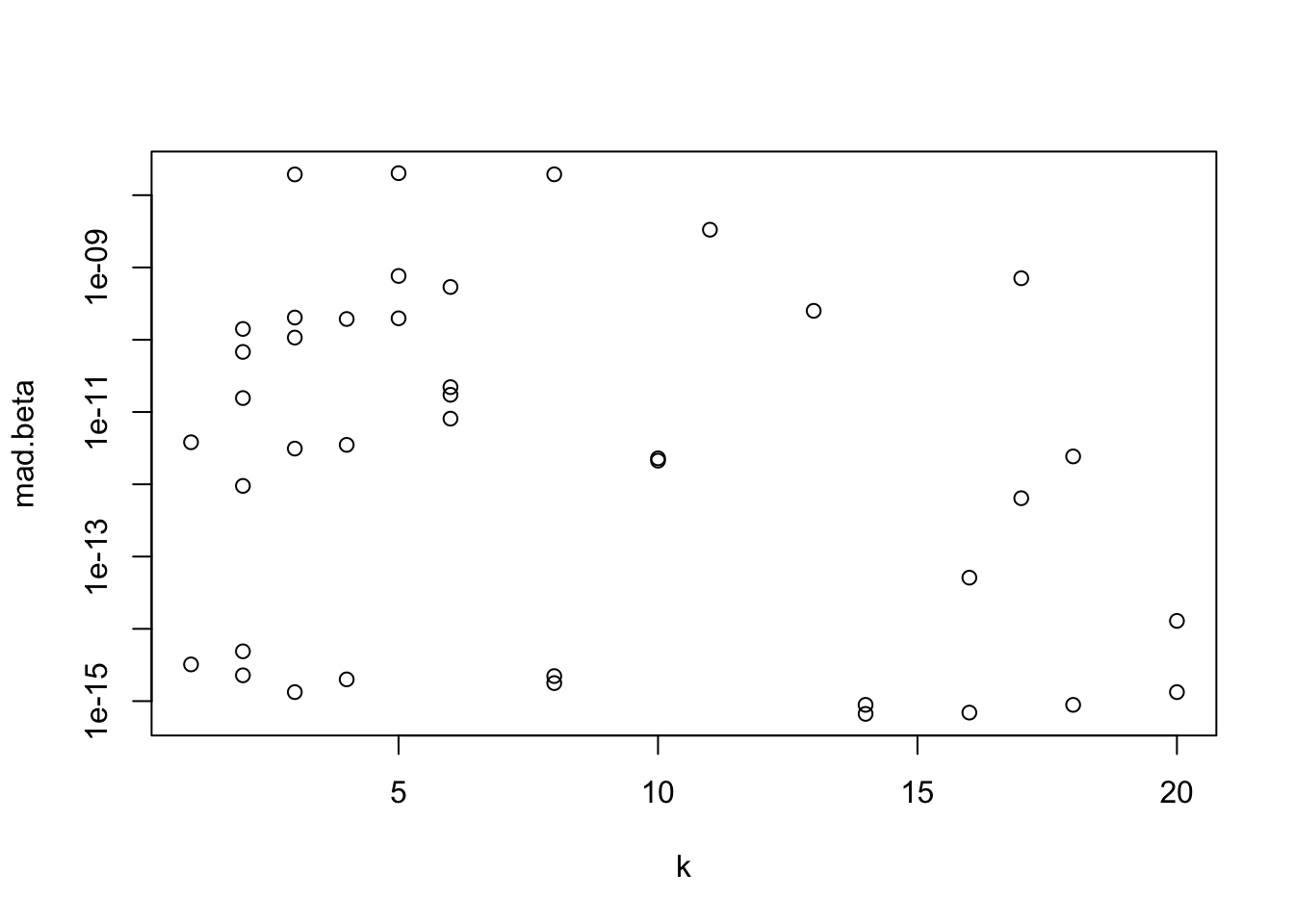
Study Convergence and Timings
Fortran vs. R
Regarding execution speed, a key question is whether it’s worth the effort to code part of the calculations in a compiled language such as Fortran, C, or C++, as compared to just using R. Let’s explore this by coding the gradient vector calculation in R and timing it against the new Fortran code. Also write a function making the Fortran routine easy to call when computing the gradient.
The code below makes use of the facts that \(\frac{\partial \log \text{expit}(x)}{\partial x} = \text{expit}(-x) = 1 - \text{expit}(x)\) and \(\frac{\partial \text{expit}(x)}{\partial x} = \text{expit(x)}(1 - \text{expit(x)})\). The philosophy of this code is that nothing is calculated unless it is relevant, which makes for more lines of code. For example, the code does not create extra intercepts to yield probabilities of 0 or 1, but instead handles each case Y=0, Y=\(k\), \(0 < \text{Y} < k\) separately. For the non-interior levels of Y the gradient is very simple as probabilities are expits and not differences.
grad <- function(alpha, beta, x, y) {
k <- length(alpha)
p <- length(beta)
f <- plogis
xb <- as.vector(x %*% matrix(beta, nrow=p))
xb <- as.vector(x %*% beta)
P1 <- P2 <- numeric(n)
i0 <- y == 0
ik <- y == k
ib <- y > 0 & y < k
P1[i0] <- 1e0
P2[i0] <- f(alpha[1] + xb[i0])
P1[ik] <- f(alpha[k] + xb[ik])
P2[ik] <- 0e0
P1[ib] <- f(alpha[y[ib] ] + xb[ib])
P2[ib] <- f(alpha[y[ib] + 1] + xb[ib])
pq1 <- P1 * (1e0 - P1)
pq2 <- P2 * (1e0 - P2)
P <- P1 - P2
U <- rep(0e0, k + p)
U[1] <- - sum(1e0 - P[i0])
U[k] <- U[k] + sum(1e0 - P[ik])
# Gradiant for intercepts
if(k > 1) for(m in 1 : k) { # only interior y values create complexity
if(m < k) U[m] <- U[m] + sum(pq1[y == m] / P[y == m])
if(m > 1) U[m] <- U[m] - sum(pq2[y == m - 1] / P[y == m - 1])
}
# Gradient for slopes
for(m in 1 : p) {
U[k + m] <- - sum(x[i0, m] * (1e0 - P[i0]))
U[k + m] <- U[k + m] + sum(x[ik, m] * (1e0 - P[ik]))
if(k > 1) for(i in 1 : (k - 1)) {
j <- y == i
U[k + m] <- U[k + m] + sum(x[j, m] * (pq1[j] - pq2[j]) / P[j])
}
}
U
}
fgrad <- function(alpha, beta, x, y) rfort(x, y, alpha, beta)$grad
# This calls a version of the Fortran code using the alpha extension approach
fgrad2 <- function(alpha, beta, x, y) {
x <- as.matrix(x)
n <- nrow(x)
p <- ncol(x)
k <- max(y) # y assumed to be coded 0-k
.Fortran('lrmll2',
as.integer(n), as.integer(k), as.integer(p),
x, y, rep(0e0, n), rep(1e0, n), matrix(0e0, nrow=p, ncol=p),
alpha, beta, numeric(1), u=numeric(k + p), numeric(1), 2L, 0L, 0L)$u
}But is the elegance of following the letter of the proportional odds model’s definition worth the trouble? What if we used the trick that is most often used in MLE and Bayesian modeling where we define extra intercepts so that all values of Y appear to be interior values and the same difference in probabilities can be computed everywhere, and we did not use special cases to compute derivatives of log likelihood components? Specifically we can write the model as the following, with y = \(0, 1, \ldots, k\) and \(\text{expit}(x) = \frac{1}{1 + \exp(-x)}\).
\[\Pr(Y \geq y) = \text{expit}(\alpha_y + X\beta)\]
by expanding the original vector of intercepts \(\alpha\) by adding \(\alpha_0 = 100\) and \(\alpha_{k+1} = -100\). Then \(\Pr(Y = y) = \text{expit}(\alpha_y + X\beta) - \text{expit}(\alpha_{y+1} + X\beta)\) for any \(y=0, \ldots, k\). The \(\pm 100\) is chosen so that \(\text{expit}(x)\) is indistinguishable from 1 and 0.
We need to run some computational tests to make sure that the upcoming shortcuts do not cause any computational inefficiencies or inaccuracies.
# Check that R computes expit very quickly for extreme values of x
tim(smallvals = plogis(rep( 1, 100000)),
m50 = plogis(rep(-50, 100000)),
p50 = plogis(rep( 50, 100000)))Per-run execution time in seconds, averaged over 10 runs
smallvals m50 p50
0.0011 0.0009 0.0009 # Check that taking the log of probabilities is as accurate as
# using plogis' special log probability calculation
x <- seq(-50, 50, by=1); m(log(plogis(x)) - plogis(x, log=TRUE))[1] 8.881784e-16So it appears that the “intercept extension” approach will not cause any numerical problems. To code this method while computing the gradient, we need the derivative of the log of the difference in probabilities (call this \(Q = P_1 - P_2\)) given above. Consider a general parameter \(\theta\) which may be one of the (interior) \(\alpha\)s or one of the \(\beta\)s.
\[\frac{\partial \log(Q)}{\partial\theta} = \frac{\frac{\partial P_1}{\partial\theta} - \frac{\partial P_2}{\partial\theta}}{Q}\] Since the main part of \(\frac{\partial \text{expit}(x)}{\partial\theta} = \text{expit(x)}(1 - \text{expit(x)})\),
\[\frac{\partial P_1}{\partial\theta} = P_1 (1 - P_1) \frac{\partial(\alpha_y + X\beta)}{\partial\theta}\] \[\frac{\partial P_2}{\partial\theta} = P_2 (1 - P_2) \frac{\partial(\alpha_{y + 1} + X\beta)}{\partial\theta}\]
\(\frac{\partial(\alpha_{y} + X\beta)}{\partial\theta}\) is the 0/1 indicator function \([y=j]\) when \(\theta = \alpha_{j}\) and is \(X_{j}\) when \(\theta = \beta_{j}\). Now code this in R.
grad2 <- function(alpha, beta, x, y) {
k <- length(alpha)
p <- length(beta)
xb <- as.vector(x %*% matrix(beta, nrow=p))
xb <- as.vector(x %*% beta)
alpha <- c(100e0, alpha, -100e0)
# Must add 1 to y to compute P1 and P2 since index starts at 1, not 0
P1 <- plogis(alpha[y + 1] + xb)
P2 <- plogis(alpha[y + 2] + xb)
Q <- P1 - P2
pq1 <- P1 * (1e0 - P1)
pq2 <- P2 * (1e0 - P2)
U <- numeric(k + p)
# Gradiant for intercepts
for(m in 1 : k)
U[m] <- sum((pq1 * (y == m) - pq2 * (y + 1 == m)) / Q)
# Use element-wise multiplication then get the sum for each column
# Element-wise = apply the same value of the weights to each row of x
U[(k + 1) : (k + p)] <- colSums(x * (pq1 - pq2) / Q)
U
}Check that grad and grad2 yield the same answer and check their relative speeds.
set.seed(1)
n <- 50000; p <- 50; k <- 100
x <- matrix(rnorm(n * p), nrow=n)
y <- sample(0 : k, n, TRUE)
stopifnot(length(unique(y)) == k + 1)
alpha <- seq(-6, 6, length=k)
beta <- runif(p, -0.5, 0.5)
tim(g1 = grad( alpha, beta, x, y),
g2 = grad2(alpha, beta, x, y),
reps = 5) # creates ResPer-run execution time in seconds, averaged over 5 runs
g1 g2
0.918 0.072 m(Res$g1 - Res$g2) # maximum absolute difference[1] 4.183676e-11Even though the streamlined code in grad2 required evaluating a few quantities that are known to be 0 or 1, its vectorization resulted in significantly faster R code. Later this will be compared with the speed of Fortran code.
NoteFortran Code for Gradient
Here is the central part of the Fortran code for computing the gradient vector. Fortran is blazing fast and easier to learn than C and C++, so more users may wish to translate some execution-time critical portions of their R code to Fortran 2018. R makes it easy to include Fortran code in packages, and it is also easy to include Fortran functions in RStudio sessions.
u = 0_dp
! All obs with y=0
! The derivative of log expit(x) wrt x is expit(-x)
! Prob element is expit(-alpha(1) - lp)
u(1) = - sum(wt(i0) * (1_dp - d(i0)))
if(p > 0) then
do l = 1, p
u(k + l) = - sum(wt(i0) * x(i0, l) * (1_dp - d(i0)))
end do
end if
! All obs with y=k
! Prob element is expit(alpha(k) + lp)
u(k) = u(k) + sum(wt(ik) * (1_dp - d(ik)))
if(p > 0) then
do l = 1, p
u(k + l) = u(k + l) + sum(wt(ik) * x(ik, l) * (1_dp - d(ik)))
end do
end if
! All obs with 0 < y < k
if(nb > 0) then
do ii = 1, nb
i = ib(ii)
j = y(i)
! For p1, D() = 1 for alpha(j), 0 for alpha(j+1)
! For p2, D() = 0 for alpha(j), 1 for alpha(j+1)
u(j) = u(j) + wt(i) * v1(i) / d(i)
u(j + 1) = u(j + 1) - wt(i) * v2(i) / d(i)
if(p > 0) then
do l = 1, p
u(k + l) = u(k + l) + wt(i) * x(i, l) * (v1(i) - v2(i)) / d(i)
end do
end if
end doThis code can be streamlined using the \(\alpha\) extension approach:
ealpha = [100d0, alpha, -100d0]
p1 = expit(ealpha(y + 1) + lp)
p2 = expit(ealpha(y + 2) + lp)
q = p1 - p2
pq1 = p1 * (1_dp - p1)
pq2 = p2 * (1_dp - p2)
do j = 1, k
u(j) = sum((pq1 * merge(1_dp, 0_dp, y == j) - &
pq2 * merge(1_dp, 0_dp, y + 1 == j)) / (q / wt))
end do
if(p > 0) then
do j = 1, p
u(k + j) = sum(x(:, j) * (pq1 - pq2) / (q / wt))
end do
end ifBut this code runs faster (this is the code tested below):
do i = 1, n
w = q(i) / wt(i)
do j = 1, k
if(y(i) == j) u(j) = u(j) + pq1(i) / w
if(y(i) + 1 == j) u(j) = u(j) - pq2(i) / w
end do
if(p > 0) then
do j = 1, p
u(k + j) = u(k + j) + x(i, j) * (pq1(i) - pq2(i)) / w
end do
end if
end doFirst let’s compare accuracy and speed of two ways of coding the gradient calculation in Fortran (click above to see both versions).
tim(Fortran = fgrad (alpha, beta, x, y),
Fortran2 = fgrad2(alpha, beta, x, y), reps=44/10 )Per-run execution time in seconds, averaged over 4.4 runs
Fortran Fortran2
0.007500000 0.009545455 m(Res$Fortran - Res$Fortran2)[1] 6.366463e-12Though it produces the same result to within \(7\times 10^{-12}\), the streamlined Fortran is \(1.5\times\) slower than the longer Fortran code.
Run the R grad2 function defined above, and the Fortran routine included in the new rms package, for \(n=50,000\), \(p=50\) predictors, and \(k=100\) intercepts.
# Check agreement of R and Fortran code
tim(R = grad2(alpha, beta, x, y),
Fortran = fgrad(alpha, beta, x, y), reps=40 )Per-run execution time in seconds, averaged over 40 runs
R Fortran
0.061750 0.007875 m(Res$R - Res$Fortran)[1] 6.366463e-12We see that the compiled Fortran code is \(> 7\times\) faster than the R code. In a nutshell Fortran allows you to not worry about vectorizing calculations, allowing for simpler code (there are many functions in Fortran for vectorizing operations but these are used more for brevity than for speed).
A more vectorized version of the code, written by ChatGPT, gave completely incorrect results but only ran faster by a ratio of 0.84. After much prompting, ChatGPT could only get the right answer if it re-wrote the code to be very inefficient by using excessive loops.
NoteChatGPT’s Compact But Non-Working Code
As streamlined as this code is, it does not improve execution time over my R grad function, taking 1.1s to run on the data given above while yielding the wrong answer.
gradient_proportional_odds <- function(alpha, beta, X, Y) {
n <- nrow(X) # Number of observations
p <- ncol(X) # Number of predictors
k <- length(alpha) # Number of thresholds (max Y value)
# Compute linear predictors
eta <- X %*% beta # n x 1 vector
# Expand eta to match dimensions with alpha
eta_matrix <- matrix(eta, n, k, byrow = FALSE) # n x k matrix
# Compute expit(alpha_y + eta) for all thresholds y
eta_alpha <- eta_matrix + matrix(alpha, n, k, byrow = TRUE)
expit_vals <- 1 / (1 + exp(-eta_alpha)) # n x k matrix of expit values
# Compute probabilities for P(Y = y)
expit_upper <- cbind(1, expit_vals) # P(Y >= 0) = 1
expit_lower <- cbind(expit_vals, 0) # P(Y >= k+1) = 0
prob_Y <- expit_upper[, 1:k] - expit_lower[, 1:k] # P(Y = y)
# Indicator matrix for observed Y
Y_ind <- matrix(0, n, k)
for (i in 1:k) Y_ind[, i] <- as.numeric(Y == (i - 1))
# Compute weights (observed minus predicted probabilities)
weights <- (Y_ind - prob_Y)
# Gradients w.r.t. alpha
grad_alpha <- colSums(weights)
# Gradients w.r.t. beta
d_expit <- expit_vals * (1 - expit_vals) # Derivative of expit
grad_beta <- numeric(p)
for (j in 1:p) {
grad_beta[j] <- sum(weights * d_expit * X[, j])
}
# Combine gradients
grad <- c(grad_alpha, grad_beta)
return(grad)
}The hessian requires about a factor of \(\frac{k + p}{2}\) more calculations than the gradient when computed inefficiently, so the Fortran code pays off even more when using hessian-based optimization algorithms or computing the final covariance matrix. The lrmll Fortran code called by the new lrm.fit, and ormll called by orm.fit, capitalize on the tri-band diagonal form of the hessian for the cumulative probability model. In rms 7.0-0 lrm.fit and orm.fit were completely re-written to benefit from Fortran code anx to use the Matrix package for more efficient sparse matrix handling.
Efficient Computation of the hessian for General Cumulative Probability Models
The lrmll Fortran subroutine computes the hessian very efficiently for the proportional odds model (logit link), making use of simplifications for the logistic model. Now consider general links. For \(Y = 1, ..., k - 1, P(Y = j)\) is written in terms of the cumulative probability function \(f\) by \(f(\alpha_{j} + X\beta) - f(\alpha_{j+1} + X\beta)\). We need all the second partial derivatives of the log of this difference in cumulative probabilities. Let’s simplify the expression to \(f(a + \beta x) - f(b + \beta x)\). ChatGPT provided the following results, which I simplified somewhat and corrected a sign error in \(\frac{\partial^2 g}{\partial b \ \partial \beta}\).
- Let \(g(a, b, \beta, x) = \log\left(f(a + \beta x) - f(b + \beta x)\right)\)
- Let \(F(a, b, \beta, x) = f(a + \beta x) - f(b + \beta x)\)
- Substitute \(d\) for \(F(a, b, \beta, x)\) post differentiation
- Divide all the second partial derivatives below by \(d^2\)
\[ \begin{aligned} \frac{\partial^2 g}{\partial a^2} &= d f''(a + \beta x) - f'(a + \beta x)^2 \\ \frac{\partial^2 g}{\partial b^2} &= -d f''(b + \beta x) - f'(b + \beta x)^2 \\ \frac{\partial^2 g}{\partial \beta^2} &= x^2 d \big(f''(a + \beta x) - f''(b + \beta x)\big) - x^{2} \big(f'(a + \beta x) - f'(b + \beta x)\big)^2 \\ \frac{\partial^2 g}{\partial a \partial b} &= f'(a + \beta x) \cdot f'(b + \beta x) \\ \frac{\partial^2 g}{\partial a \partial \beta} &= x d f''(a + \beta x) - x f'(a + \beta x) \cdot \big(f'(a + \beta x) - f'(b + \beta x)\big) \\ \frac{\partial^2 g}{\partial b \partial \beta} &= -x d f''(b + \beta x) + x f'(b + \beta x) \cdot \big(f'(a + \beta x) - f'(b + \beta x)\big) \end{aligned} \]
For derivatives with respect only to \(\beta\), substitute \(x_{i} x_{j}\) for \(x^2\) to get second partial derivatives with respect to \(\beta_{i}\) and \(\beta_{j}\).
Let \(d = 1 - f\) for \(Y=0\) and \(d = f\) otherwise. For the interior values of \(Y\), first consider \(Y=0\) which has probability \(d = 1 - f(a + x \beta)\). The second partial derivatives are, when multiplied by \((1 - f)^{2} = d^{2}\),
\[ \begin{aligned} \frac{\partial^2 g}{\partial a^2} &= - f'^{2} - df'' \\ \frac{\partial^2 g}{\partial \beta^2} &= - x^{2} \big(f'^{2} + df''\big) \\ \frac{\partial^2 g}{\partial a\partial\beta} &= - x\big(f'^{2} - df''\big) \end{aligned} \]
Here \(f\) stands for \(f(a + \beta x)\) etc.
For \(Y=k\) the hessian elements are, when multiplied by \(f^2\),
\[ \begin{aligned} \frac{\partial^2 g}{\partial a^2} &= d f'' - f'^{2} \\ \frac{\partial^2 g}{\partial \beta^2} &= x^{2} \big(d f'' - f'^{2}\big) \\ \frac{\partial^2 g}{\partial a\partial\beta} &= x\big(d f'' - f'^{2}\big) \end{aligned} \]
All these formulas are implemented in the ormll Fortran subroutine used in the 6.9-1 version of rms.
NoteUse of Jacobians to Translate hessian on One Scale To Another Scale
Sometimes it’s easier to derive second derivatives on the original scale without logging, and using a Jacobian to translate to the other scale. ChatGPT provided the following Jacobian solution for our example. This is not used in the Fortran code because it might slow it down a bit. I believe that MASS::polr uses the Jacobian approach.
To systematically compute and represent the transformation of the second partial derivatives of \(F(a, b, \beta, x)\) into the second partial derivatives of \(g(a, b, \beta, x) = \log(F(a, b, \beta, x))\), we organize the derivatives into a hessian matrix and apply the transformation rules using Jacobian operations.
Step 1: Define the hessian Matrix for \(F\)
The hessian matrix of \(F(a, b, \beta, x)\) with respect to \((a, b, \beta)\) is: \[ \mathbf{H}_F = \begin{bmatrix} \frac{\partial^2 F}{\partial a^2} & \frac{\partial^2 F}{\partial a \partial b} & \frac{\partial^2 F}{\partial a \partial \beta} \\ \frac{\partial^2 F}{\partial b \partial a} & \frac{\partial^2 F}{\partial b^2} & \frac{\partial^2 F}{\partial b \partial \beta} \\ \frac{\partial^2 F}{\partial \beta \partial a} & \frac{\partial^2 F}{\partial \beta \partial b} & \frac{\partial^2 F}{\partial \beta^2} \end{bmatrix}. \]
Using the expressions for second partial derivatives derived earlier: \[ \begin{aligned} \frac{\partial^2 F}{\partial a^2} &= f''(a + \beta x), \quad \frac{\partial^2 F}{\partial b^2} = -f''(b + \beta x), \quad \frac{\partial^2 F}{\partial \beta^2} = x^2 \big(f''(a + \beta x) - f''(b + \beta x)\big), \\ \frac{\partial^2 F}{\partial a \partial b} &= 0, \quad \frac{\partial^2 F}{\partial a \partial \beta} = x f''(a + \beta x), \quad \frac{\partial^2 F}{\partial b \partial \beta} = -x f''(b + \beta x). \end{aligned} \]
Thus: \[ \mathbf{H}_F = \begin{bmatrix} f''(a + \beta x) & 0 & x f''(a + \beta x) \\ 0 & -f''(b + \beta x) & -x f''(b + \beta x) \\ x f''(a + \beta x) & -x f''(b + \beta x) & x^2 \big(f''(a + \beta x) - f''(b + \beta x)\big) \end{bmatrix}. \]
Step 2: Define the Transformation for \(g = \log(F)\)
We apply the chain rule: \[ g = \log(F) \implies \frac{\partial g}{\partial z} = \frac{1}{F} \frac{\partial F}{\partial z}, \] \[ \frac{\partial^2 g}{\partial z \partial w} = \frac{1}{F} \frac{\partial^2 F}{\partial z \partial w} - \frac{1}{F^2} \frac{\partial F}{\partial z} \frac{\partial F}{\partial w}. \]
This can be written compactly in matrix form.
Step 3: Matrix Transformation
Let:
- \(\nabla F = \begin{bmatrix} \frac{\partial F}{\partial a} & \frac{\partial F}{\partial b} & \frac{\partial F}{\partial \beta} \end{bmatrix}^\top\)
- \(\mathbf{H}_F\) be the hessian matrix of \(F\)
- \(F\) be the scalar value of \(F(a, b, \beta, x)\).
The hessian of \(g(a, b, \beta, x)\) is given by: \[ \mathbf{H}_g = \frac{1}{F} \mathbf{H}_F - \frac{1}{F^2} \nabla F \nabla F^\top. \]
Explanation:
- \(\frac{1}{F} \mathbf{H}_F\): Scales the hessian of \(F\) by \(\frac{1}{F}\)
- \(\frac{1}{F^2} \nabla F \nabla F^\top\): Accounts for the interaction of first derivatives of \(F\)
Step 4: Components of \(\nabla F\)
From earlier: \[ \frac{\partial F}{\partial a} = f'(a + \beta x), \quad \frac{\partial F}{\partial b} = -f'(b + \beta x), \quad \frac{\partial F}{\partial \beta} = x \big(f'(a + \beta x) - f'(b + \beta x)\big). \]
Thus: \[ \nabla F = \begin{bmatrix} f'(a + \beta x) \\ -f'(b + \beta x) \\ x \big(f'(a + \beta x) - f'(b + \beta x)\big) \end{bmatrix}. \]
Step 5: Compute \(\nabla F \nabla F^\top\)
The outer product \(\nabla F \nabla F^\top\) is: \[ \nabla F \nabla F^\top = \begin{bmatrix} f'(a + \beta x)^2 & -f'(a + \beta x) f'(b + \beta x) & f'(a + \beta x) x \big(f'(a + \beta x) - f'(b + \beta x)\big) \\ -f'(a + \beta x) f'(b + \beta x) & f'(b + \beta x)^2 & -f'(b + \beta x) x \big(f'(a + \beta x) - f'(b + \beta x)\big) \\ f'(a + \beta x) x \big(f'(a + \beta x) - f'(b + \beta x)\big) & -f'(b + \beta x) x \big(f'(a + \beta x) - f'(b + \beta x)\big) & x^2 \big(f'(a + \beta x) - f'(b + \beta x)\big)^2 \end{bmatrix}. \]
Final Hessian of \(g\)
The hessian of \(g(a, b, \beta, x)\) is: \[ \mathbf{H}_g = \frac{1}{F} \mathbf{H}_F - \frac{1}{F^2} \nabla F \nabla F^\top. \]
Substitute \(\mathbf{H}_F\) and \(\nabla F \nabla F^\top\) explicitly to get the full matrix. This provides the second derivatives of \(g\) in terms of \(F\), its derivatives, and the structure of \(f\).
Check Speed of NR, LM, nlminb, and glm.fit
glm.fit is tailored to be efficient when Y is binary and there is no penalization, by using iteratively weighted least squares. How does it stack up against NR and nlminb? Let’s try fitting a large binary logistic model.
set.seed(1)
n <- 100000; p <- 100
X <- matrix(rnorm(n * p), nrow=n)
y <- sample(0 : 1, n, TRUE)
tim(NR = lrm.fit(X, y, compstats=FALSE),
LM = lrm.fit(X, y, opt_method='LM', compstats=FALSE),
nlminb = lrm.fit(X, y, opt_method='nlminb', compstats=FALSE),
glm.fit = glm.fit(cbind(1, X), y), reps=3)Per-run execution time in seconds, averaged over 3 runs
NR LM nlminb glm.fit
1.315667 1.196667 1.209333 1.639000 # transx=TRUE adds 2.3s to lrm.fitCheck Convergence Under Complete Separation
Consider a simple example where there is complete separation because the predictor values are identical to the response. In this case the MLE of the intercept is \(-\infty\) and the MLE of the slope is \(\infty\). The MLEs are approximated by \(\alpha=-50, \beta=100\), yielding predicted logits of \(-50\) and \(50\) because the \(\text{expit}\)s are sufficiently close to 0.0 and 1.0.
plogis(-50, log=TRUE)[1] -50plogis( 50, log=TRUE)[1] -1.92875e-22exp(plogis(-50, log=TRUE))[1] 1.92875e-22exp(plogis( 50, log=TRUE))[1] 1See how 4 optimization algorithms fare with their default parameters and with some adjustments. In some of the trace output, the first floating point number listed is -2LL, and following that are the current \(\alpha, \beta\) estimates.
set.seed(1)
x <- sample(0 : 1, 20, TRUE)
y <- x
w <- try(lrm.fit(x, y, opt_method='NR', trace=1)) # default opt_methodIteration:1 -2LL:26.92047 Max |gradient|:9.6 Max |change in parameters|:4.166667
Iteration:2 -2LL:4.704224 Max |gradient|:1.754066 Max |change in parameters|:2.249045
Iteration:3 -2LL:1.588994 Max |gradient|:0.616103 Max |change in parameters|:2.08089
Iteration:4 -2LL:0.5685801 Max |gradient|:0.2233137 Max |change in parameters|:2.028578
Iteration:5 -2LL:0.2071309 Max |gradient|:0.0817248 Max |change in parameters|:2.010364
Iteration:6 -2LL:0.07592908 Max |gradient|:0.03000809 Max |change in parameters|:2.003793
Iteration:7 -2LL:0.02789647 Max |gradient|:0.01103173 Max |change in parameters|:2.001393
Iteration:8 -2LL:0.01025764 Max |gradient|:0.004057316 Max |change in parameters|:2.000512
Iteration:9 -2LL:0.003772913 Max |gradient|:0.001492464 Max |change in parameters|:2.000188
Iteration:10 -2LL:0.001387888 Max |gradient|:0.000549028 Max |change in parameters|:2.000069
Iteration:11 -2LL:0.0005105632 Max |gradient|:0.0002019736 Max |change in parameters|:2.000025
Iteration:12 -2LL:0.0001878241 Max |gradient|:7.430157e-05 Max |change in parameters|:2.000009
Iteration:13 -2LL:6.90964e-05 Max |gradient|:2.733397e-05 Max |change in parameters|:2.000003
Iteration:14 -2LL:2.541911e-05 Max |gradient|:1.00556e-05 Max |change in parameters|:2.000001w <- try(lrm.fit(x, y, opt_method='LM', trace=1))Iteration:1 -2LL:4.726435 Max |gradient|:9.6 Max |change in parameters|:4.15697
Iteration:2 -2LL:1.596267 Max |gradient|:1.760569 Max |change in parameters|:2.249698
Iteration:3 -2LL:0.5711236 Max |gradient|:0.6183991 Max |change in parameters|:2.081206
Iteration:4 -2LL:0.2080488 Max |gradient|:0.2241376 Max |change in parameters|:2.028698
Iteration:5 -2LL:0.07626438 Max |gradient|:0.08202485 Max |change in parameters|:2.010408
Iteration:6 -2LL:0.0280195 Max |gradient|:0.03011806 Max |change in parameters|:2.003809
Iteration:7 -2LL:0.01030286 Max |gradient|:0.01107213 Max |change in parameters|:2.001399
Iteration:8 -2LL:0.003789542 Max |gradient|:0.004072171 Max |change in parameters|:2.000514
Iteration:9 -2LL:0.001394004 Max |gradient|:0.001497928 Max |change in parameters|:2.000189
Iteration:10 -2LL:0.0005128133 Max |gradient|:0.0005510379 Max |change in parameters|:2.00007
Iteration:11 -2LL:0.0001886518 Max |gradient|:0.0002027129 Max |change in parameters|:2.000026
Iteration:12 -2LL:6.94009e-05 Max |gradient|:7.457357e-05 Max |change in parameters|:2.000009
Iteration:13 -2LL:2.553113e-05 Max |gradient|:2.743404e-05 Max |change in parameters|:2.000003
Iteration:14 -2LL:9.392375e-06 Max |gradient|:1.009241e-05 Max |change in parameters|:2.000001w <- try(lrm.fit(x, y, opt_method='nlminb', trace=1)) 0: 26.920467: -0.405465 0.00000
1: 5.9001181: -1.83776 3.67925
2: 1.9469377: -2.99693 5.99700
3: 0.69222129: -4.04687 8.09673
4: 0.25163200: -5.06435 10.1316
5: 0.092171572: -6.07067 12.1442
6: 0.033854569: -7.07298 14.1489
7: 0.012447190: -8.07383 16.1506
8: 0.0045780905: -9.07414 18.1512
9: 0.0016840535: -10.0743 20.1514
10: 0.00061951084: -11.0743 22.1515
11: 0.00022790289: -12.0743 24.1515
12: 8.3840460e-05: -13.0743 26.1515
13: 3.0843137e-05: -14.0743 28.1515
14: 1.1346550e-05: -15.0743 30.1515
15: 4.1741617e-06: -16.0743 32.1515
16: 1.5355882e-06: -17.0743 34.1515
17: 5.6491130e-07: -18.0743 36.1515
18: 2.0781925e-07: -19.0743 38.1515
19: 7.6452432e-08: -20.0743 40.1515
20: 2.8125276e-08: -21.0743 42.1515
21: 1.0346714e-08: -22.0743 44.1515
22: 3.8063437e-09: -23.0743 46.1515
23: 1.4002772e-09: -24.0743 48.1515
24: 5.1513283e-10: -25.0743 50.1515
25: 1.8950352e-10: -26.0743 52.1515
26: 6.9714901e-11: -27.0743 54.1515
27: 2.5648816e-11: -28.0743 56.1515
28: 9.4360075e-12: -29.0743 58.1515
29: 3.4692249e-12: -30.0743 60.1515
30: 1.2789769e-12: -31.0743 62.1515
31: 4.7073456e-13: -32.0743 64.1515
32: 1.6875390e-13: -33.0743 66.1515
33: 6.2172489e-14: -34.0743 68.1515
34: 2.6645353e-14: -35.0743 70.1515
35: 8.8817842e-15: -36.0743 72.1515
36: 0.0000000: -37.0743 74.1515
37: 0.0000000: -37.0743 74.1515w <- try(lrm.fit(x, y, opt_method='glm.fit', trace=1))Deviance = 3.368709 Iterations - 1
Deviance = 1.16701 Iterations - 2
Deviance = 0.4207147 Iterations - 3
Deviance = 0.1536571 Iterations - 4
Deviance = 0.0563787 Iterations - 5
Deviance = 0.02072057 Iterations - 6
Deviance = 0.007619969 Iterations - 7
Deviance = 0.002802865 Iterations - 8
Deviance = 0.001031067 Iterations - 9
Deviance = 0.0003793016 Iterations - 10
Deviance = 0.0001395364 Iterations - 11
Deviance = 5.133244e-05 Iterations - 12
Deviance = 1.888413e-05 Iterations - 13
Deviance = 6.947082e-06 Iterations - 14
Deviance = 2.555688e-06 Iterations - 15
Deviance = 9.401851e-07 Iterations - 16
Deviance = 3.458748e-07 Iterations - 17
Deviance = 1.272402e-07 Iterations - 18
Deviance = 4.680906e-08 Iterations - 19
Deviance = 1.722009e-08 Iterations - 20
Deviance = 6.33492e-09 Iterations - 21
Deviance = 2.330491e-09 Iterations - 22
Deviance = 8.573409e-10 Iterations - 23
Deviance = 3.15401e-10 Iterations - 24
Deviance = 1.160316e-10 Iterations - 25
Deviance = 4.268585e-11 Iterations - 26
Deviance = 1.570299e-11 Iterations - 27
Deviance = 5.782042e-12 Iterations - 28w <- try(lrm.fit(x, y, opt_method='BFGS', trace=1))initial value 26.920467
iter 10 value 0.000153
iter 20 value 0.000017
iter 30 value 0.000004
iter 40 value 0.000001
iter 50 value 0.000000
final value 0.000000
stopped after 50 iterationsnlminbtook 37 iterations, going so far that the hessian matrix was singular. It should have stopped with 10.glm.fittook 28 iterations; should have stopped with 10BFGS: stopped after 50 iterations; should have stopped with 10
Now specify arguments to lrm.fit that are tuned to this task.
w <- lrm.fit(x, y, opt_method='nlminb', abstol=1e-3, trace=1) 0: 26.920467: -0.405465 0.00000
1: 5.9001181: -1.83776 3.67925
2: 1.9469377: -2.99693 5.99700
3: 0.69222129: -4.04687 8.09673
4: 0.25163200: -5.06435 10.1316
5: 0.092171572: -6.07067 12.1442
6: 0.033854569: -7.07298 14.1489
7: 0.012447190: -8.07383 16.1506
8: 0.0045780905: -9.07414 18.1512
9: 0.0016840535: -10.0743 20.1514
10: 0.00061951084: -11.0743 22.1515w <- lrm.fit(x, y, opt_method='glm.fit', reltol=1e-3, trace=1)Deviance = 3.368709 Iterations - 1
Deviance = 1.16701 Iterations - 2
Deviance = 0.4207147 Iterations - 3
Deviance = 0.1536571 Iterations - 4
Deviance = 0.0563787 Iterations - 5
Deviance = 0.02072057 Iterations - 6
Deviance = 0.007619969 Iterations - 7
Deviance = 0.002802865 Iterations - 8
Deviance = 0.001031067 Iterations - 9
Deviance = 0.0003793016 Iterations - 10
Deviance = 0.0001395364 Iterations - 11
Deviance = 5.133244e-05 Iterations - 12w <- lrm.fit(x, y, opt_method='BFGS', reltol=1e-4, trace=1)initial value 26.920467
iter 10 value 0.000153
final value 0.000100
convergedThe tolerance parameters are too large to use when infinite coefficients are not a problem.
Check Algorithms With k=1000
For timings that follow, compstats=FALSE is specified to lrm.fit so that we can focus on computationally efficiencies of various optimization algorithms. Some of the differences in run times may not seem to be consequential, but once extremely large datasets are analyzed or one needs to fit models in a bootstrap or Monte Carlo simulation loop, the differences in speed will matter.
When the number of distinct Y values is large, and this far exceeds the number of predictors (\(k >> p\)), the rms lrm and orm function are highly efficient. They take into account the sparsity of the intercept portion of the hessian matrix, which is tri-band diagonal and has only \(2\times k\) nonzero values for \(k+1\) distinct Y values, taking the matrix’s symmetry into account. Outside of lrm, orm and SAS JMP, ordinal regression fitting software treats the hessian matrix as being \(k\times k\) and does not capitalize on sparsity.
Note that for Bayesian MCMC this is not an issue as posterior sampling does not need the hessian.
set.seed(1)
n <- 10000; k <- 1000
x <- rnorm(n); y <- sample(0:k, n, TRUE)
length(unique(y))[1] 1001tim(orm = orm.fit(x, y, eps=1e-9, compstats=FALSE),
ormlm = lrm.fit(x, y, opt_method='LM', compstats=FALSE),
bfgs = lrm.fit(x, y, opt_method='BFGS', compstats=FALSE, maxit=100),
nlminb = lrm.fit(x, y, opt_method='nlminb', compstats=FALSE),
nr = lrm.fit(x, y, opt_method='NR', compstats=FALSE),
nlm = lrm.fit(x, y, opt_method='nlm', compstats=FALSE),
polr = MASS::polr(factor(y) ~ x, control=list(reltol=1e-10)),
reps= 2)Per-run execution time in seconds, averaged over 2 runs
orm ormlm bfgs nlminb nr nlm polr
0.0085 0.0140 0.0375 0.3215 0.0095 6.9605 6.4010 smod() deviance max_abs_u iter
orm 137142.5 1.008812e-09 2
ormlm 137142.5 5.287811e-04 3
bfgs 137142.5 2.376188e+00 4
nlminb 137142.5 2.046306e-09 3
nr 137142.5 7.625981e-05 2
nlm 137142.5 7.625981e-05 1
polr 137142.5 NA NA
Maximum |difference in coefficients|, Maximum |relative difference|
worst ratio of covariance matrices Comparison Max |difference| Max |rel diff| Cov ratio
1 orm vs. ormlm 4.528191e-06 2.116413e-05 1.020062
2 orm vs. bfgs 6.991343e-06 3.950698e-04
3 orm vs. nlminb 2.194293e-15 8.487308e-15 1.000000
4 orm vs. nr 1.376879e-15 5.475644e-15 1.000000
5 orm vs. nlm 4.136309e-07 3.812140e-07 1.001368
6 orm vs. polr 9.637588e-06 1.359060e-05
7 ormlm vs. bfgs 3.000666e-06 3.747458e-04
8 ormlm vs. nlminb 4.528191e-06 2.116413e-05 1.020062
9 ormlm vs. nr 4.528191e-06 2.116413e-05 1.020062
10 ormlm vs. nlm 4.219032e-06 2.103439e-05 1.021457
11 ormlm vs. polr 8.539945e-06 3.049453e-05
12 bfgs vs. nlminb 6.991343e-06 3.950698e-04
13 bfgs vs. nr 6.991343e-06 3.950698e-04
14 bfgs vs. nlm 6.776204e-06 3.949523e-04
15 bfgs vs. polr 9.425718e-06 4.030520e-04
16 nlminb vs. nr 8.695423e-16 3.063504e-15 1.000000
17 nlminb vs. nlm 4.136309e-07 3.812140e-07 1.001368
18 nlminb vs. polr 9.637588e-06 1.359060e-05
19 nr vs. nlm 4.136309e-07 3.812140e-07 1.001368
20 nr vs. polr 9.637588e-06 1.359060e-05
21 nlm vs. polr 9.231301e-06 1.326760e-05 nlminb is slower then NR because to run nlminb requires converting the Hession from a sparse Matrix into a regular dense matrix.
Check Timing and Agreement for n=100000, k=10, p=5
Check timing and calculation agreement for n=100000, 10 intercepts, 5 predictors.
set.seed(1)
n <- 100000
y <- sample(0 : 10, n, TRUE)
x1 <- rnorm(n)
x2 <- rnorm(n)
x3 <- rnorm(n)
x4 <- rnorm(n)
x5 <- rnorm(n)
X <- cbind(x1, x2, x3, x4, x5)
tim(old.lrm.fit = olrm(X, y, eps=1e-7),
nr = lrm.fit(X, y, opt_method='NR', compstats=FALSE),
lm = orm.fit(X, y, opt_method='LM', compstats=FALSE),
nlm = lrm.fit(X, y, opt_method='nlm', compstats=FALSE),
nlminb = lrm.fit(X, y, opt_method='nlminb', compstats=FALSE, transx=TRUE),
nlminb.notransx = lrm.fit(X, y, opt_method='nlminb', compstats=FALSE, transx=FALSE),
bfgs = lrm.fit(X, y, opt_method='BFGS', compstats=FALSE),
bfgs.reltol = lrm.fit(X, y, opt_method='BFGS',
compstats=FALSE, reltol=1e-12),
polr = MASS::polr(factor(y) ~ X,
control=list(reltol=1e-10)),
reps = 5)Per-run execution time in seconds, averaged over 5 runs
old.lrm.fit nr lm nlm nlminb
0.1468 0.0838 0.0732 0.4820 0.1082
nlminb.notransx bfgs bfgs.reltol polr
0.0774 0.3912 0.5786 2.4018 smod() deviance max_abs_u iter
old.lrm.fit 479562.9 6.575185e-12 NA
nr 479562.9 1.992454e-07 3
lm 479562.9 4.246613e-05 3
nlm 479562.9 5.051226e-02 1
nlminb 479562.9 1.992456e-07 3
nlminb.notransx 479562.9 1.992452e-07 3
bfgs 479562.9 6.987317e-01 7
bfgs.reltol 479562.9 3.683980e-05 19
polr 479562.9 NA NA
Maximum |difference in coefficients|, Maximum |relative difference|
worst ratio of covariance matrices Comparison Max |difference| Max |rel diff| Cov ratio
1 old.lrm.fit vs. nr 5.404639e-16 9.835782e-15 1.000000
2 old.lrm.fit vs. lm 1.964277e-09 3.686249e-08 1.000000
3 old.lrm.fit vs. nlm 3.004074e-06 2.122140e-05 1.000202
4 old.lrm.fit vs. nlminb 1.053798e-11 4.463472e-11 1.000000
5 old.lrm.fit vs. nlminb.notransx 1.053800e-11 4.461566e-11 1.000000
6 old.lrm.fit vs. bfgs 9.057305e-06 7.174198e-04
7 old.lrm.fit vs. bfgs.reltol 5.712939e-08 1.703831e-06
8 old.lrm.fit vs. polr 5.977469e-06 2.409730e-03
9 nr vs. lm 1.964277e-09 3.686250e-08 1.000000
10 nr vs. nlm 3.004074e-06 2.122140e-05 1.000202
11 nr vs. nlminb 1.053798e-11 4.462649e-11 1.000000
12 nr vs. nlminb.notransx 1.053799e-11 4.460743e-11 1.000000
13 nr vs. bfgs 9.057305e-06 7.174198e-04
14 nr vs. bfgs.reltol 5.712939e-08 1.703831e-06
15 nr vs. polr 5.977469e-06 2.409730e-03
16 lm vs. nlm 3.002323e-06 2.123986e-05 1.000202
17 lm vs. nlminb 1.954251e-09 3.688524e-08 1.000000
18 lm vs. nlminb.notransx 1.954251e-09 3.688522e-08 1.000000
19 lm vs. bfgs 9.056084e-06 7.173837e-04
20 lm vs. bfgs.reltol 5.903326e-08 1.726185e-06
21 lm vs. polr 5.978924e-06 2.409739e-03
22 nlm vs. nlminb 3.004063e-06 2.122136e-05 1.000202
23 nlm vs. nlminb.notransx 3.004063e-06 2.122136e-05 1.000202
24 nlm vs. bfgs 8.867603e-06 7.344671e-04
25 nlm vs. bfgs.reltol 3.059332e-06 2.243214e-05
26 nlm vs. polr 7.995997e-06 2.398944e-03
27 nlminb vs. nlminb.notransx 3.778083e-17 2.518821e-14 1.000000
28 nlminb vs. bfgs 9.057301e-06 7.174198e-04
29 nlminb vs. bfgs.reltol 5.713988e-08 1.703864e-06
30 nlminb vs. polr 5.977476e-06 2.409730e-03
31 nlminb.notransx vs. bfgs 9.057301e-06 7.174198e-04
32 nlminb.notransx vs. bfgs.reltol 5.713988e-08 1.703864e-06
33 nlminb.notransx vs. polr 5.977476e-06 2.409730e-03
34 bfgs vs. bfgs.reltol 9.069540e-06 7.167658e-04
35 bfgs vs. polr 1.347117e-05 2.800575e-03
36 bfgs.reltol vs. polr 5.951212e-06 2.410693e-03 Other Speed Tests
n=1,000,000, p=100 predictors, k=50 intercepts
lrm.fit: 13.5s (13.6 withopt_method=nlminb, 120s withopt_method='BFGS')orm.fit: 9sMASS::polr: 70s without the hessian
n=300,000, p=20, k=299,999
lrm.fit: 2.25sorm.fit: 2s
Execution time is proportional to \(k \times p\)
Check Impact of initglm and transx
Generate a sample of 500 with 30 predictors and 269 levels of Y where a subset of the predictors are strongly related to Y and there are collinearities.
set.seed(1)
n <- 500
p <- 30
x <- matrix(runif(n * p), nrow=n)
x[, 1:8] <- x[, 1:8] + 2 * x[, 9]
s <- varclus(~ x)$hclust
plot(as.dendrogram(s), horiz=TRUE, axes=FALSE,
xlab=expression(paste('Spearman ', rho^2)))
rh <- seq(0, 1, by=0.1)
axis(1, at=1 - rh, labels=format(rh))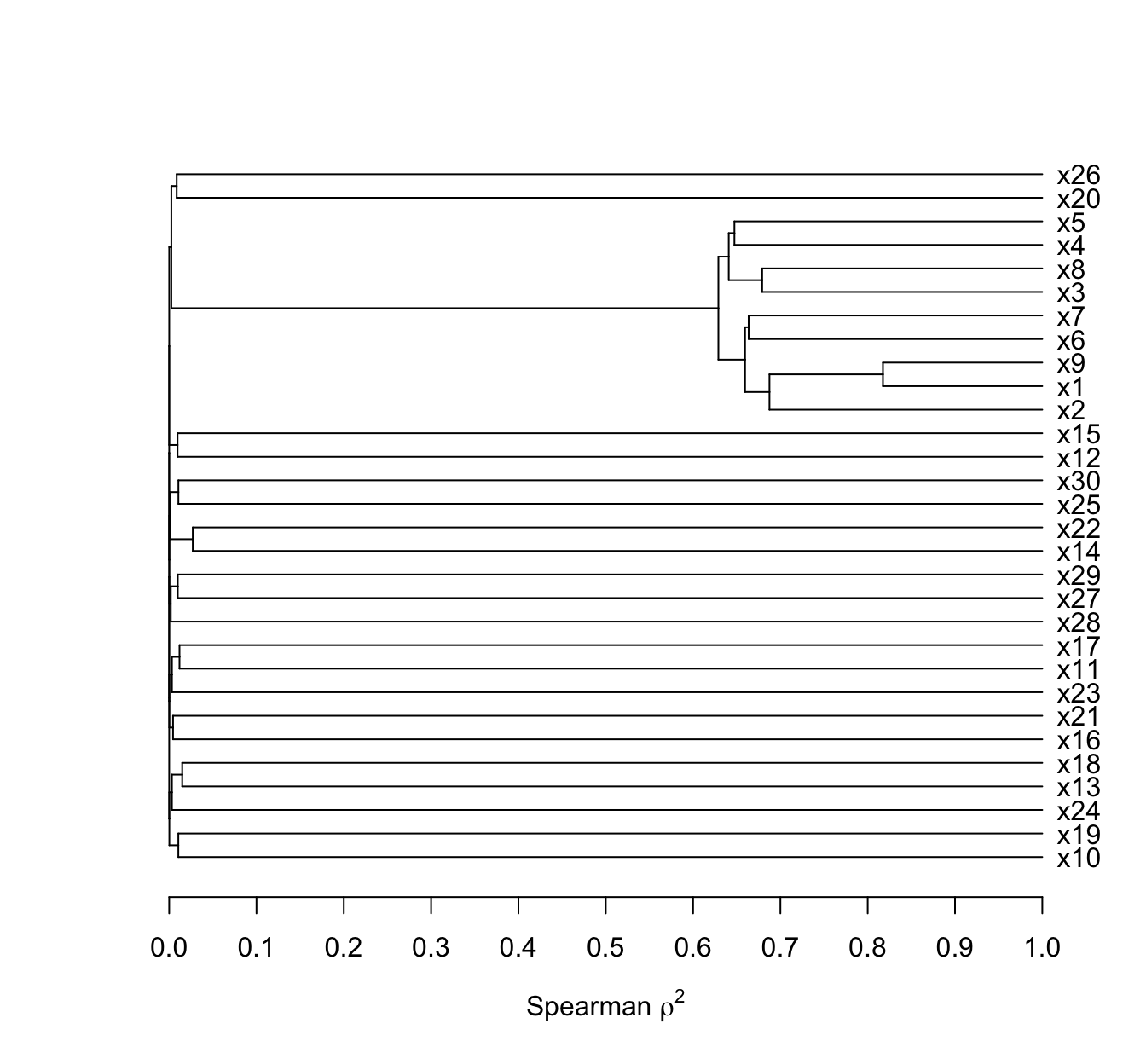
y <- x[, 1] + 2 * x[, 2] + 3 * x[, 3] + 4 * x[, 4]+ 5 * x[, 5] +
3 * runif(n, -1, 1)
y <- round(y, 1)
length(unique(y))[1] 269f <- function(..., opt_method='NR')
lrm.fit(x, y, compstats=FALSE, opt_method=opt_method, maxit=1000, ...)
# f(initglm=TRUE) (using nlminb) would not work: NA/NaN gradient evaluation
# This did not happen without collinearities
tim(default = f(),
transx = f(transx=TRUE),
nlm = f(opt_method='nlm'),
bfgs = f(opt_method='BFGS'),
nlminb = f(opt_method='NR'),
reps = 10 )Per-run execution time in seconds, averaged over 10 runs
default transx nlm bfgs nlminb
0.0136 0.0163 0.5946 0.2671 0.0210 smod() deviance max_abs_u iter
default 3879.848 6.112532e-05 7
transx 3879.848 6.112532e-05 7
nlm 3879.848 6.112532e-05 6
bfgs 3879.848 5.367424e-03 510
nlminb 3879.848 6.112532e-05 7
Maximum |difference in coefficients|, Maximum |relative difference|
worst ratio of covariance matrices Comparison Max |difference| Max |rel diff| Cov ratio
1 default vs. transx 7.418667e-15 8.758898e-16 1.000000
2 default vs. nlm 1.063035e-05 5.990158e-07 1.000291
3 default vs. bfgs 1.902524e-05 4.646345e-06
4 default vs. nlminb 0.000000e+00 0.000000e+00 1.000000
5 transx vs. nlm 1.063035e-05 5.990158e-07 1.000291
6 transx vs. bfgs 1.902524e-05 4.646345e-06
7 transx vs. nlminb 7.418667e-15 8.758898e-16 1.000000
8 nlm vs. bfgs 1.629260e-05 4.555452e-06
9 nlm vs. nlminb 1.063035e-05 5.990158e-07 1.000291
10 bfgs vs. nlminb 1.902524e-05 4.646345e-06 lrm.fit vs. orm.fit as k \(\uparrow\)
The fitting function for rms::orm, orm.fit, uses sparse hessian matrices so that the computation time is roughly proportional to \(n (3k + p^{2} + kp)\) where \(k\) is the number of intercepts and \(p\) is the number of predictors. Computation of the hessian in lrm.fit needs about \(n (k + p)^{2}\) computations, but some parts of the computation are faster and there is some overhead of handling sparse matrices in orm.fit. Let’s explore execution time as a function of \(k\) when \(n=10000, p=30\) and \(k\) varies. There should be very little difference.
if(! file.exists('breakeven.rds')) {
set.seed(1)
n <- 10000
p <- 30
ks <- seq(100, 10000, by=200)
l <- length(ks)
t1 <- t2 <- d <- numeric(l)
x <- matrix(rnorm(n * p), nrow=n)
for(i in 1 : l) {
cat(ks[i], ' ')
y <- rep(0 : ks[i], length=n)
t1[i] <- stim(for(j in 1:20) f <- rms::lrm.fit(x, y)) / 20
t2[i] <- stim(for(j in 1:20) g <- rms::orm.fit(x, y)) / 20
d [i] <- m(coef(f) - coef(g))
}
w <- llist(ks, t1, t2, d)
saveRDS(w, 'breakeven.rds')
} else {
w <- readRDS('breakeven.rds')
ks <- w$ks; t1 <- w$t1; t2 <- w$t2; d <- w$d
}
# Make sure coefficients agree
range(d)[1] 8.881784e-16 1.532996e-12plot(ks, t1, type='b', xlab='k', ylab='Time, seconds', ylim=c(0.02, 0.18))
points(ks, t2, col='red')
lines (ks, t2, col='red')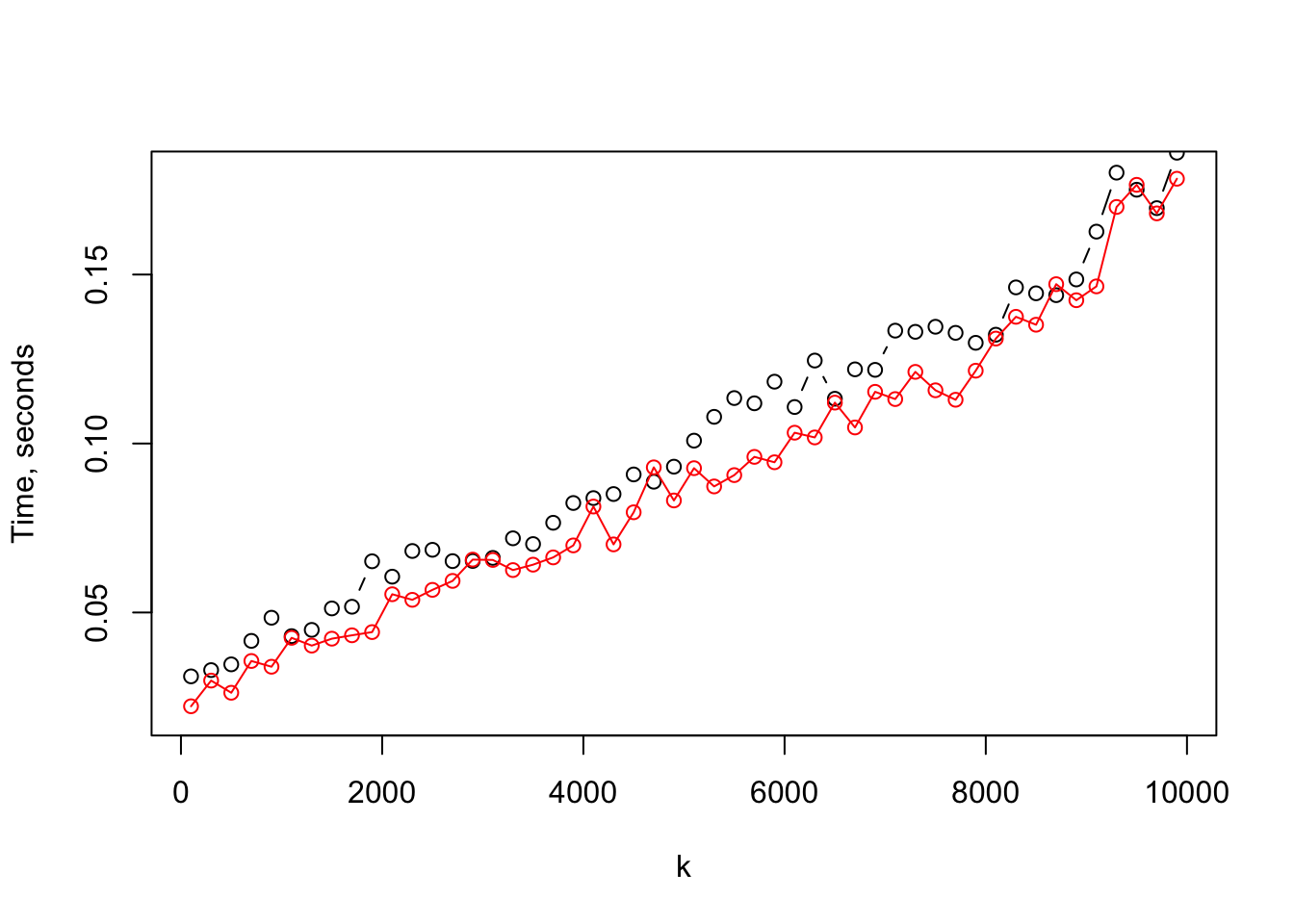
Execution time for both functions is linear in k. orm is consistently a little faster than lrm. Since the code in the orm.fit Fortran ormll subroutine is more general, currently implementing 5 link functions, there is no real reason to maintain separate code. In the future I plan to merge the functions to minimize duplication, and having an lrm front-end for orm for backward compatibility.
Better Understanding Convergence with BFGS Optimizer
Using the same simulated data just used with k=20, use BFGS to fit an ordinal model with relative tolerance varying from \(10^{-2}\) to \(10^{-20}\). Estimates are compared to orm. In addition to comparing parameter estimates as done above we also compute differences in units of standard errors as computed by orm.
set.seed(1)
y <- sample(0:20, n, TRUE)
g <- orm(y ~ x, eps=1e-10)
se <- sqrt(diag(vcov(g, intercepts='all')))
length(se)[1] 50if(file.exists('bfgs-reltol.rds')) d <- readRDS('bfgs-reltol.rds') else {
d <- NULL
for(i in 2 : 20) {
cat(i, '')
s <- stim({
for(j in 1:5)
f <- lrm.fit(x, y, compstats=FALSE,
opt_method='BFGS',
maxit=1000,
reltol=10^(-i))
} )
w <- data.frame(i, elapsed=s / 5, maxu=m(f$u),
maxbeta=m(coef(g) - coef(f)),
maxbeta.per.se=m((coef(g) - coef(f)) / se),
deviance=tail(f$deviance, 1),
iter=tail(f$iter, 1))
d <- rbind(d, w)
}
rownames(d) <- NULL
saveRDS(d, 'bfgs-reltol.rds')
}
d i elapsed maxu maxbeta maxbeta.per.se deviance iter
1 2 0.0150 1.474752e+02 2.559219e-02 1.485374e+00 60853.10 1
2 3 0.0156 1.474752e+02 2.559219e-02 1.485374e+00 60853.10 1
3 4 0.0520 4.754120e+01 8.310188e-03 4.823241e-01 60843.74 3
4 5 0.0676 2.731752e+01 6.488538e-03 3.765954e-01 60843.47 4
5 6 0.1164 2.570406e+01 4.628291e-03 1.152693e-01 60842.69 10
6 7 0.1634 3.232073e+00 4.015687e-03 9.284606e-02 60842.60 16
7 8 0.4220 1.849727e+00 4.627223e-04 1.288221e-02 60842.57 55
8 9 0.4202 4.694068e-01 8.486176e-04 2.144243e-02 60842.57 53
9 10 0.5654 1.027168e-01 1.576543e-04 3.340893e-03 60842.57 75
10 11 0.3670 3.118309e-02 5.997566e-05 1.292625e-03 60842.57 52
11 12 0.5104 1.435433e-02 6.238079e-06 1.344461e-04 60842.57 71
12 13 0.3986 9.525472e-03 1.005773e-05 2.167691e-04 60842.57 56
13 14 0.3882 1.054183e-03 1.688144e-06 3.638369e-05 60842.57 57
14 15 0.5556 1.669547e-03 1.222338e-06 2.832486e-05 60842.57 70
15 16 0.4710 4.720818e-04 1.373869e-07 7.956884e-06 60842.57 60
16 17 0.3992 4.720818e-04 1.373869e-07 7.956884e-06 60842.57 60
17 18 0.3950 4.720818e-04 1.373869e-07 7.956884e-06 60842.57 60
18 19 0.4126 4.720818e-04 1.373869e-07 7.956884e-06 60842.57 60
19 20 0.4522 4.720818e-04 1.373869e-07 7.956884e-06 60842.57 60z <- c(deviance=8, beta=10, beta.se=6, grad=15) # minimum i for which success achieved
h <- function() abline(v=z, col=gray(0.60))
h <- function() {} # remove this line to show reference lines
par(mfrow=c(2, 3), mar=c(4, 4, 1, 1), las=1, mgp=c(2.8, .45, 0))
with(d, {
plot(i, elapsed, type='l'); h()
plot(i, maxu, type='l', log='y'); h()
plot(i, maxbeta, type='l', log='y'); h()
plot(i, maxbeta.per.se, type='l'); h()
plot(i, deviance - 3879, type='l', log='y'); h()
plot(i, iter, type='l', log='y'); h()
})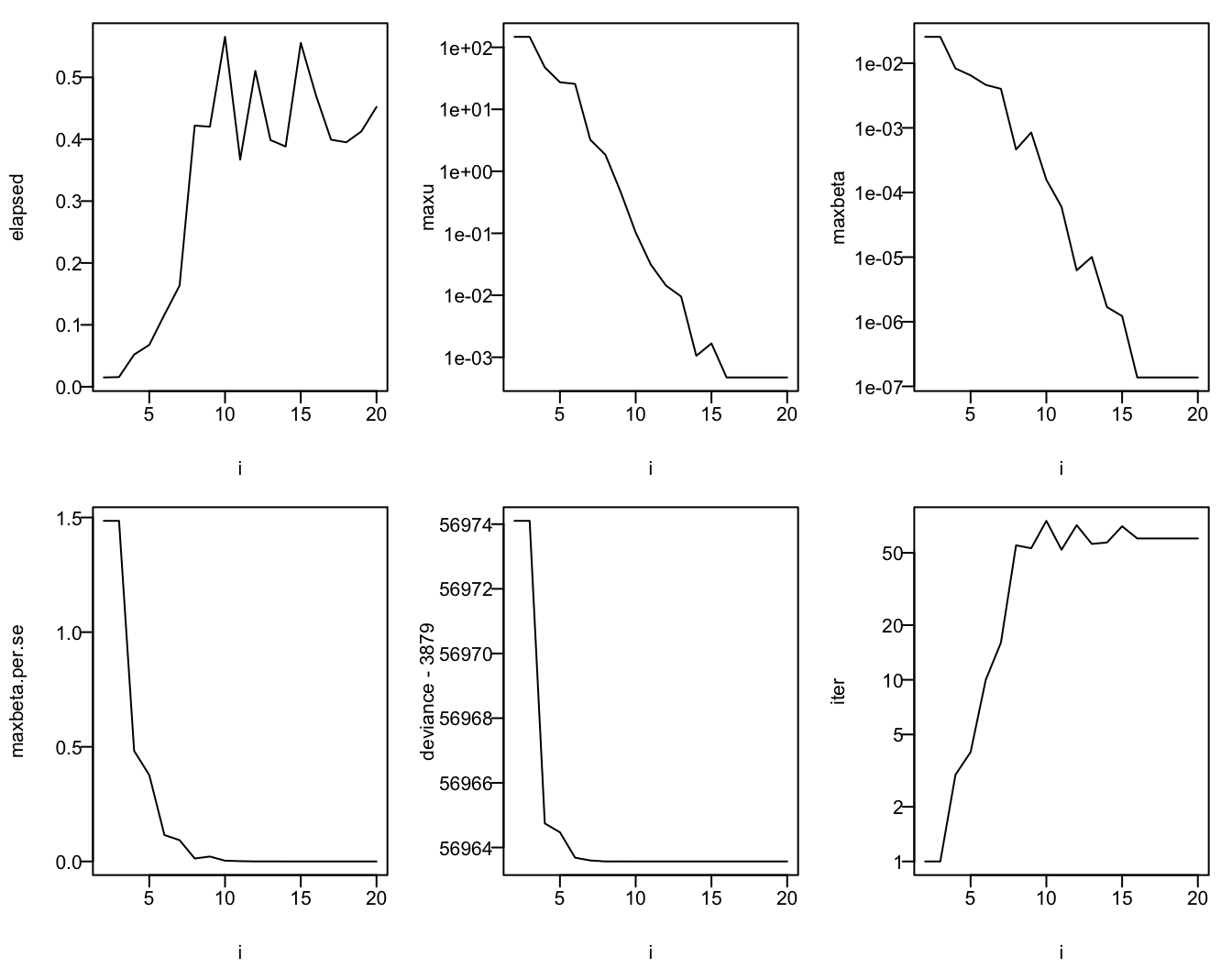
NULLSee that stochastic convergence, as judged by deviance, occurs by the time the relative tolerance is \(10^{-8}\), by \(10^{-10}\) to control maximum absolute parameter difference, by \(10^{-6}\) to get parameter estimates to within 0.06 standard error, and by \(10^{-15}\) to achieve gradients \(< 10^{-4}\) in absolute value.
When using BFGS a recommendation is to use a relative tolerance of \(10^{-8}\) to nail down estimates to the extent that it matters precision-wise, and use \(10^{-10}\) to achieve reproducibility.
Recall that BFGS is only appealing when the number of intercepts is large, you don’t need the covariance matrix, and you are not using orm.
Matrix Inversion
The information matrix (negative hessian) must be inverted to compute the variance-covariance matrix. The default inversion method in R is the solve function, which defaults to using the LU decomposition. This is a fast algorithm, but the Cholesky decomposition is faster and behaves as well as LU numerically. Another approach uses the QR decomposition, implemented in the qr.solve function. Let’s compare speed and accuracy of the three approaches when applied to a high-dimensional almost-singular matrix.
# ChatGPT created this function to generate an almost-singular symmetric
# positive definite matrix of dimension p x p
genas <- function(p, epsilon = 1e-8) {
# Generate a random symmetric positive definite matrix
A <- matrix(rnorm(p^2), p, p)
A <- A + t(A) + p * diag(p) # Symmetric and positive definite
# Modify eigenvalues to make the matrix almost singular
eigen_decomp <- eigen(A)
eigen_decomp$values[p] <- epsilon # Set the smallest eigenvalue close to zero
eigen_decomp$vectors %*% diag(eigen_decomp$values) %*% t(eigen_decomp$vectors)
}
set.seed(3)
x <- genas(750, 1e-9)
x[1:3, 1:3] [,1] [,2] [,3]
[1,] 748.051108 -1.0242634 0.3929600
[2,] -1.024263 747.2599805 0.9261079
[3,] 0.392960 0.9261079 745.6809913# LU method
stime(for(i in 1:3) a <- solve(x))Elapsed time: 0.489smad(x, solve(a)) # reverse the inversion and compare to x mad relmad
0.0001918367 0.0006802723 m(diag(750) - x %*% a) # compare x inverse * x to identity matrix[1] 2.636021e-05# QR
stime(for(i in 1:3) b <- qr.solve(x, tol=1e-13))Elapsed time: 1.576smad(x, qr.solve(b, tol=1e-13)) mad relmad
0.0002055301 0.0007529110 m(diag(750) - x %*% b)[1] 3.14796e-05# Cholesky
stime(for(i in 1:3) ch <- chol2inv(chol(x)))Elapsed time: 0.331smad(x, chol2inv(chol(ch))) # mean |difference| and mean relative difference mad relmad
0.0002321373 0.0008178099 m(diag(750) - x %*% ch) # mean |difference|[1] 2.07157e-05QR takes significantly longer and offers no accuracy advantange. Inversion via Cholesky decomposition was almost twice as fast as LU, though both methods took less than \(\frac{1}{4}\) of a second to invert a \(750\times 750\) matrix. Cholesky was a little more accurate in getting the product of the original matrix and its inverse closer to an identity matrix. Cholesky was very slightly worse in recovering the original matrix by inverting its inverse.
One of the reasons lrm.fit and orm.fit are more efficient in rms 7.0 is that the entire information matrix is not inverted upon convergence when creating the final fit object. Much use is made of the Matrix package for efficient storage and computation of sparse matrices, and only the 3 minimal submatrices that make up the information matrix are stored. These are operated on quite generally by the new rms infoMxop function, which is called by the vcov method to invert pieces of the information matrix only as needed. During Newton-type updating, the Matrix solve function is used, which is quite fast as it uses sparse representations and does not actually invert the Hession but solves for the inverse of the hessian multiplied by the gradient vector.
Here is an example where only elements 10:20 from the inverse of a 1000 x 1000 matrix are obtained. This type of coding is used in infoMxop.
# Create a 1000 x 1000 symmetric positive definite matrix
set.seed(1)
x <- matrix(rnorm(10000 * 1000), ncol=1000)
v <- crossprod(x)
i <- 10:20 # submatrix of v inverse that we want
l <- length(i)
w <- matrix(0, 1000, l)
w[cbind(i, 1:l)] <- 1 # w is all zeros except for 1 in i elements
sum(w)[1] 11stime(vi <- solve(v, w)[i, , drop=FALSE])Elapsed time: 0.118sdim(vi)[1] 11 11stime(vi_slow <- solve(v))Elapsed time: 0.367srange(vi - vi_slow[i, i])[1] 0 0What about inverting the kind of sparse matrices that ordinal models deal with? Let’s build one using the Matrix package and rms::infoMxop.
require(Matrix)
p <- 200
k <- 20000
set.seed(1)
w <- list(a = cbind(runif(k), runif(k)),
b = v[1:p, 1:p],
ab= matrix(runif(k * p), k, p) )
stime(z <- infoMxop(w))Elapsed time: 0.15sobject.size(w)32641088 bytesobject.size(z)97282280 bytes# Sparse representation of intercept components used by infoMxop
ia <- Matrix::bandSparse(k, k=c(0,1), diagonals=w$a, symmetric=TRUE)
object.size(ia)561720 bytes# Time to invert this sparse matrix
stime(via <- Matrix::solve(ia))Elapsed time: 1.984sdim(via)[1] 20000 20000# The inverse of a tri-band diagonal matrix is dense but can be represented efficiently
object.size(via)383980824 byteslength(via@x)[1] 31991591# Compute size needed if did not make use of sparsity
8 * (p + k) ^ 2[1] 3264320000# Get covariate portion of inverted matrix
stime(ub <- infoMxop(w, i='x'))Elapsed time: 0.371s# Get the first intercept and beta portion of the inverse
i <- c(1, (k + 1) : (k + p))
stime(u <- infoMxop(w, i=i)) # 26s for i=one elementElapsed time: 48.088sdim(u); dim(ub); range(u[-1, -1] - ub)[1] 201 201[1] 200 200[1] -5.009692e-17 4.220257e-17# Don't try this: infoMxop(w, invert=TRUE))The specialized method with i='x' for getting just the portion of the inverse corresponding to the \(\beta\)s is very fast. Otherwise there are speed challenges but the sparse representation does allow the overall inverse to be computed, something not possible with naive matrix calculations.
Now consider execution time for computing the standard errors of predicted values . Consider a predicted value of the form \(\hat{\alpha}_{j} + X\hat{\beta}\) involving a single intercept \(\hat{\alpha}_j\). Let \(V\) be the variance-covariance matrix for \(\theta = [\alpha_{j}, \beta]\) where \(\beta\) is a vector of length \(p\). Let the \(m\times (p + 1)\) matrix \(X\) consisting of a column of ones followed by \(p\) columns of predictor settings. \(m\) is the number of observations for which predictions are sought. Standard errors of interest are square roots of the diagonal of the variance-covariance matrix \(W\) for \(\hat{Y} = X\hat{\theta}\), where \(W = XVX'\) is an \(m\times m\) matrix.
This also applies to contrasts where differences in \(X\) are substituted for \(X\).
rms::infoMxop makes computations such as \(W\) efficient using the following strategy. Let \(J\) be a matrix that is mainly zeros but with ones in positions that indicate which elements of \(V^{-1}\) to compute. Let \(I\) denote the information matrix for the entire model, with \(k + p\) rows and columns. Concentrate on computation of \(VX'\). Instead of computing \(I^{-1}\) by itself, compute only the needed elements of it by computing solve(I, J) to get \(V\). But we quickly want to post-multiply by \(X'\) so use solve(I, JX'). Let’s see how fast this is when there are 299,999 intercepts.
set.seed(1)
n <- 300000; p <- 10; x <- matrix(runif(n * p), ncol=p); y <- 1 : n
k <- length(unique(y)) - 1
f <- orm(y ~ x)
# Get intercept number corresponding to median of y
j <- f$interceptRef
# Compute all parameter numbers needed
h <- c(j, (k + 1) : (k + p))
info <- f$info.matrix
mdim(info) # show dimensions of submatrices a b ab
rows 299999 10 299999
columns 2 10 10# Form covariate values for 2 observations for predicting
X <- rbind(c(1, rep(.2, p)), c(1, rep(.6, p)))
X [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11]
[1,] 1 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2
[2,] 1 0.6 0.6 0.6 0.6 0.6 0.6 0.6 0.6 0.6 0.6# Get VX' the slow way
# system.time(infoMxop(info, invert=TRUE)[h, h] %*% t(X)) 5.4s for k=9999
et <- stime(a <- infoMxop(info, i=h, B=t(X)))Elapsed time: 0.315sa [,1] [,2]
y>=150000 1.933352e-04 -4.675176e-05
x[1] -3.589966e-05 1.195571e-05
x[2] -3.618740e-05 1.220834e-05
x[3] -3.635284e-05 1.205578e-05
x[4] -3.595976e-05 1.195893e-05
x[5] -3.587225e-05 1.212976e-05
x[6] -3.568398e-05 1.180846e-05
x[7] -3.607189e-05 1.206577e-05
x[8] -3.581018e-05 1.194599e-05
x[9] -3.613558e-05 1.194314e-05
x[10] -3.610595e-05 1.212468e-05stime(infoMxop(info, i=h)) # time required to compute needed submatrix of VElapsed time: 0.42sstime(infoMxop(info, i=100)) # time required to retrieve a single interceptElapsed time: 0.308sstime(infoMxop(info, i='x')) # time to get beta part of vElapsed time: 0.129s0.31 seconds to get the variance of predicted values when there are 299999 intercepts is quite sufficient! The time required to compute the portion of the inverse needed is only 0.1s longer however.
Note that in the source code for lrm and orm you’ll see a shortcut for computing the diagonal elements:
nx <- ncol(X)
X <- cbind(1, X)
nrp <- num.intercepts(f)
v <- infoMxop(info, i=c(f$interceptRef, (nrp + 1) : (nrp + nx)), B=t(X))
se <- drop(sqrt((t(v) * X) %*% rep(1, nx + 1)))What is Fast and What is Slow When \(k\) is Large
For continuous Y when there is a large number \(k\) of intercepts, here is a breakdown of what kind of computations involving ordinal regression models are fast:
- solving for the MLEs
- computing the covariance matrix for the \(\beta\)s alone and using computing it for \(\beta\) and a small number of intercepts
- any assessment that is relative (e.g., odds ratios as opposed to absolute risk estimates)
- contrasts
- Wald \(\chi^2\) tests
- likelihood ratio \(\chi^2\) tests (which don’t require covariance matrices)
- standard errors (SEs) and confidence bands for differences on the link (e.g., logit) scale
- predicted absolute quantities (exceedance probabilities, cell probabilities, means, quantiles) without SEs or confidence intervals
Slow operations for very large \(k\), e.g., \(k > 10000\):
- computing the covariance matrix for all the intercepts or for all parameters combined
For some computations it will be faster to bootstrap the model fit rather than to compute SEs and CLs. The rms bootcov function does this efficiently since it uses lrm.fit or orm.fit with compstats=FALSE to streamline the computation of MLEs from bootstrap samples.
bootcov needs all the intercepts to be represented in all bootstrap samples. To minimally group Y values to make this happen, see the new rms ordGroupBoot function.But for some “absolute” computations, run time is still exceptionally fast for large \(k\), because the entire information matrix does not need inverting, but instead the inverse is multiplied by a vector as was done above, so that solve can be used to quickly solve a system of equations instead of fully inverting. As an example let’s time the calculation of the estimation of mean Y without confidence limits, and then with them, for \(k=15000\). The Mean function uses the \(\delta\)-method to estimate the needed standard error for the normal approximation for the confidence interval for a covariate-specific population mean..
set.seed(1)
n <- 15000
y <- 1:n
x1 <- rnorm(n)
x2 <- rnorm(n)
x3 <- rnorm(n)
dd <- datadist(x1, x2, x3); options(datadist='dd')
f <- orm(y ~ x1 + x2 + x3, x=TRUE)
d <- data.frame(x1=0, x2=0, x3=0)
X <- predict(f, d, type='x') # need original design matrix for accurate CLs of means
X x1 x2 x3
1 0 0 0M <- Mean(f)
stime(print(M(predict(f, d)))) 1
7500.703
Elapsed time: 0.022sstime(print(M(predict(f, d), conf.int=0.95, X=X))) 1
7500.703
attr(,"limits")
attr(,"limits")$lower
1
7431.4
attr(,"limits")$upper
1
7570.006
Elapsed time: 0.045sstime(print(Predict(f, x1=0, x2=0, x3=0, fun=M))) x1 x2 x3 yhat lower upper
1 0 0 0 7500.703 7431.4 7570.006
Response variable (y):
Limits are 0.95 confidence limits
Elapsed time: 0.048sThis is fast because the limiting step is like this, inside the M R function:
info <- f$info.matrix
mdim(info) # show dimensions of 3 submatrices a b ab
rows 14999 3 14999
columns 2 3 3np <- sum(dim(info$ab))
np # total no. parameters = # rows and cols of info matrix[1] 15002# Multiply info inverse times B
stime(infoMxop(info, B=matrix(runif(np), ncol=1)))Elapsed time: 0.007sOther Resources
- Video by Richard McElreath explaining numerical accuracy issues in log likelihood calculations.
- R CRAN Task Views on optimizers
- Calculating OLS regression coefficients by TB Volker, which contains excellent background information about matrix algebra and timing and memory usage of various algorithms in R
- Vignettes by John Nash et al.
- R
ucminfpackage - R
nloptrpackage - R code:
lrmandlrm.fit - Fortran code:
lrmll - A cornucopia of maximum likelihood algorithms by K Lange, XJ Li, Hua Zhou, 2025.
Computing Environment
grateful::cite_packages(pkgs='Session', output='paragraph', out.dir='.',
cite.tidyverse=FALSE, omit=c('grateful', 'ggplot2'))We used R version 4.5.1 (R Core Team 2025) and the following R packages: Hmisc v. 5.2.4 (Harrell Jr 2025a), Matrix v. 1.7.3 (Bates, Maechler, and Jagan 2025), orms v. 1.0.0 (Harrell Jr 2010), rms v. 8.1.0 (Harrell Jr 2025b), survival v. 3.8.3 (Terry M. Therneau and Patricia M. Grambsch 2000; Therneau 2024).
The code was run on macOS Sequoia 15.6 on a Macbook Pro M2 Max, running on a single core.
References
Bates, Douglas, Martin Maechler, and Mikael Jagan. 2025. Matrix: Sparse and Dense Matrix Classes and Methods. https://doi.org/10.32614/CRAN.package.Matrix.
Harrell Jr, Frank E. 2010. orms: Regression Modeling Strategies. http://biostat.mc.vanderbilt.edu/rms.
———. 2025a. Hmisc: Harrell Miscellaneous. https://hbiostat.org/R/Hmisc/.
———. 2025b. rms: Regression Modeling Strategies. https://hbiostat.org/R/rms/.
R Core Team. 2025. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
Terry M. Therneau, and Patricia M. Grambsch. 2000. Modeling Survival Data: Extending the Cox Model. New York: Springer.
Therneau, Terry M. 2024. A Package for Survival Analysis in r. https://CRAN.R-project.org/package=survival.