This article provides a demonstration that the perceived non-robustness of nonlinear models for covariate adjustment in randomized trials may be less of an issue than the non-transportability of marginal so-called robust estimators.
Vanderbilt University School of Medicine Department of Biostatistics
Published
June 29, 2021
We usually treat individuals not populations. That being so, rational decision-making involves considering who to treat not whether the population as a whole should be treated. I think there are few exceptions to this. One I can think of is water-fluoridation but in most cases we should be making decisions about individuals. In short, there may be reasons on occasion to use marginal models but treating populations will rarely be one of them. — Stephen Senn, 2022
Background
In a randomized clinical trial (RCT) it is typical for several participants’ baseline characteristics to be much more predictive of the outcome variable Y than treatment is predictive of Y. Covariate adjustment in an RCT gains power by making the analysis more consistent with the data generating model, i.e., by accounting for outcome heterogeneity due to wide distributions of baseline prognostic factors. When Y is continuous and random errors have a normal distribution, it is well known that classical covariate adjustment improves power over an unadjusted analysis no matter how poorly the model fits. Lack of fit makes the random errors larger, but not as large as omitting covariates entirely. Nonlinear models such as logistic or Cox regression have no error term to absorb lack of fit, so lack of fit changes (usually towards zero) parameter estimates for all terms in the model, including the treatment effect. But the most poorly specified model is one that assumes all covariate effects are nil, i.e., one that does not adjust for covariates. Even ill-fitting models will provide more useful treatment effect estimates than a model that ignores covariates. See this for details and references about covariate adjustment in RCTs.
Because they are more easily connected to causal inference, many statisticians and epidemiologists like marginal effect estimates. Adjusted marginal effects can adjust for covariate imbalance and can take covariate distributions and resulting outcome heterogeneity into account, at least until the very last step that involves averaging over the covariate distribution. Adjusted marginal estimation does take outcome heterogeneity fully into account at all times when estimating variances. The following simple example for a single treatment arm study shows how that works.
Suppose that a sample of 100 subjects had 40 females and 60 males, and that 10 of the females and 30 of the males had disease. The marginal estimate of the probability of disease is 40/100 = 0.4, and the variance of the estimator assuming constant risk (i.e., assuming risk for females = risk for males) is \(\frac{0.4\times 0.6}{100} = 0.0024\). But with knowledge of each person’s sex we compute the variance using sex-specific risk estimates as follows. The marginal estimate combines the sex-specific estimates according to the sex distribution in the sample (a hint that what is about to happen doesn’t apply to the population). This estimate is \(0.4 \times 0.25 + 0.6 \times 0.5 = 0.4\), identical to the marginal estimate. But the true and estimated variances are not the same as that computed in the absence of knowledge of subjects’ sex. The estimated variance is \(0.4^{2}\times \frac{0.25 \times 0.75}{40} + 0.6^{2}\times \frac{0.5 \times 0.5}{60} = 0.00225\) which is smaller than 0.0024 due to the fact that the correct variance recognizes that males and females do not have the same outcome probabilities. So marginal stratified/adjusted estimation corrects the mistake of using the wrong variance formulas when computing crude marginal estimates, among other benefits such as preventing Simpson’s “paradox”. Any time you see \(\frac{p \times (1-p)}{n}\) for the variance of a proportion, remember that this formula assumes that \(p\) applies equally to all \(n\) subjects.
Turning to the more interesting two-sample problem, the adjusted marginal approach can be used to derive other interesting quantities such as marginal adjusted hazard or odds ratios. As opposed to estimating relative treatment effect conditional on covariate values, marginal estimands that account for covariates (outcome heterogeneity) are based on differences in average predicted values. Advocates of marginal treatment effect estimates for nonlinear models such as Benkeser, Díaz, Luedtke, Segal, Scharfstein, and Rosenblum1 cite as one of the main advantages of the method its robustness to model misspecification. In their approach, gains in efficiency from covariate adjustment can result, and certain types of model lack of fit are in effect averaged out. But it is this averaging that makes the resulting treatment effect in an RCT hard to interpret. Their marginal treatment effect uses a regression model as a stepping stone to an effect estimator in which estimates are made on a probability scale and averaged. For example, if Y is binary, one might fit a binary logistic regression model on the baseline covariates and the treatment variable (Benkeser et al. prefer to fit separate models by treatment, omitting the treatment indicator from each.) Then for every trial participant one obtains, for example, the estimated probability that Y=1 under treatment A, then for the same covariate values, the probability that Y=1 under treatment B. The estimates are averaged over all subjects and then subtracted to arrive at a marginal treatment effect estimate.
1 Benkeser D, Díaz I, Luedtke A, Segal J, Scharfstein D, Rosenblum M (2020): Improving precision and power in randomized trials for COVID-19 treatments using covariate adjustment, for binary, ordinal, and time-to-event outcomes. To appear in Biometrics, DOI:10.1111/biom.13377.
There are problems with this approach:
it changes the estimand to something that is not applicable to individual patient decision making
it estimates the difference in probabilities over the distribution of observed covariate values and is dependent on the covariate distributions of participants actually entering the trial
this fails to recognize that RCT participants are not a random sample from the target population; RCTs are valid when their designs result in representative treatment effects, and they do not require representative participants
to convert marginal estimates to estimates that are applicable to the population requires the RCT sample to be a probability sample and for the sampling probabilities from the population to be known
these sampling weights are almost never known; RCTs are almost always based on convenience samples
the marginal approach makes assessment of differential treatment effect (interactions) difficult
The claim that ordinary conditional estimates are not robust also needs further exploration. Here I take a simple example where there are two strong covariates—age and sex—and age has a very nonlinear true effect on the log odds that Y=1. Suppose that the investigators do not know much about flexible parametric modeling (the use of regression splines, etc.) but assume that age has a linear effect, and does the covariate adjustment assuming linearity. Suppose also that sex is omitted from the model. What happens? Is the resulting conditional odds ratio (OR) for treatment valid? We will see that it is not exactly correct, but that it can be more valid than the marginal estimate. In regression analysis one can never get the model “correct.” Instead, modeling is a question of approximating the effects of baseline variables that explain outcome heterogeneity. The better the model the more complete the conditioning and the more accurate the patient-specific effects that are estimated from the model. Omitted covariates or under-fitting strong nonlinear relationships results in effectively conditioning on only part of what one would like to know. This partial conditioning still results in useful estimates, and the estimated treatment effect will be somewhere between a fully correctly adjusted effect and a non-covariate-adjusted effect.
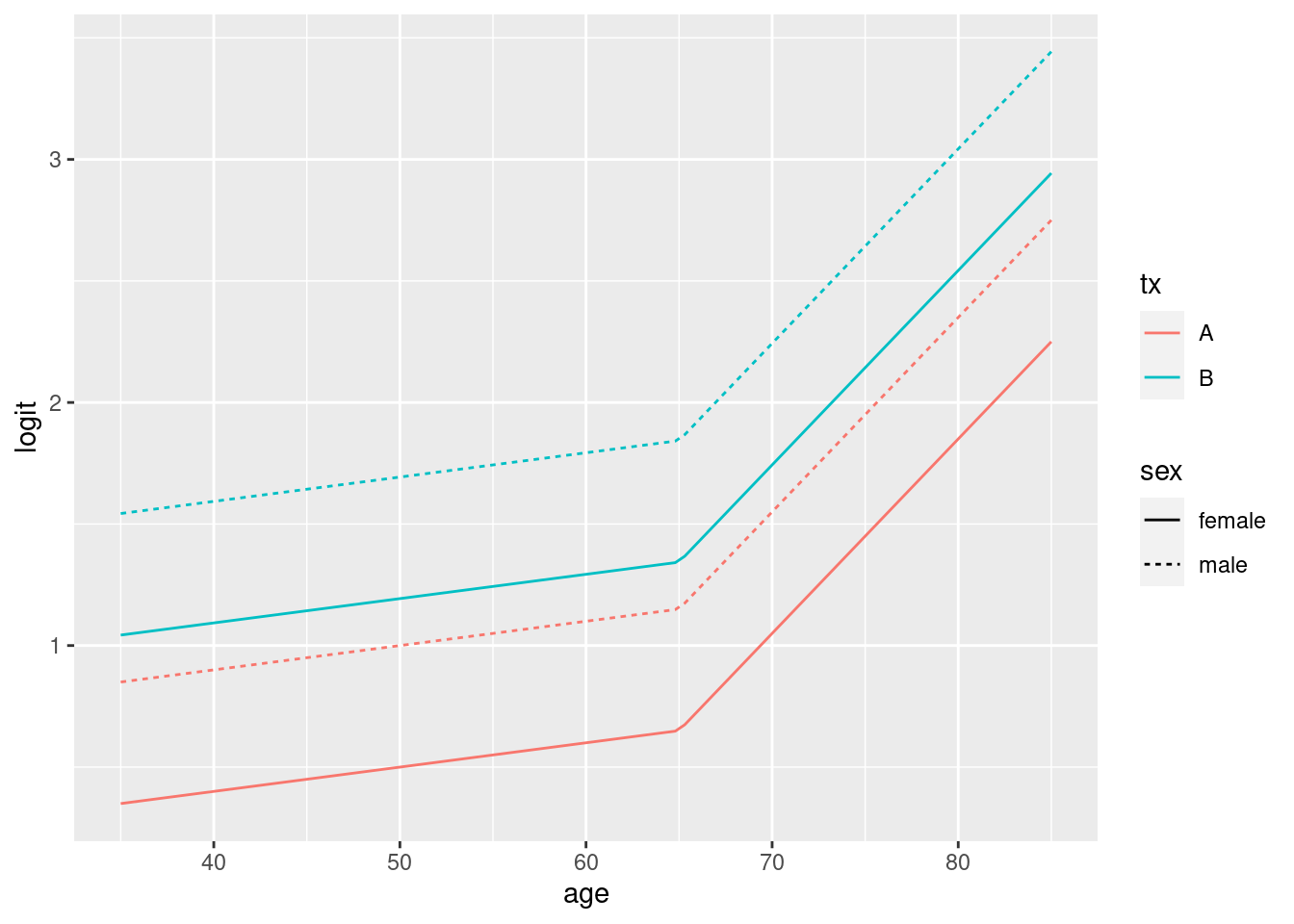
where \(A\) is age, treatment \(T\) is A or B, \(S\) is sex, and \(\mathrm{expit}\) denotes the inverse of the logit function, i.e., \(\frac{1}{1 + \exp(-u)}\). \(u_{+}\) is defined as \(u\) if \(u > 0\) and 0 otherwise, and \([u]\) is 1 if \(u\) is true and 0 otherwise. We assume the effect of using treatment B instead of treatment A raises the odds that Y=1 by a factor of 2.0, i.e., the treatment effect is OR=2 so that \(\beta_{1}=\log(2)=0.6931\). The age effect is a linear spline with slope change at 65y. Assume the true age effect is given by the initial slope of \(\beta_{2}=0.01\) and the increment in slope starting at age 65 is \(\beta_{3}=0.07\). Assume that \(\beta_{4}=0.5\) and \(\alpha=0\). Then the true relationships are given in the following graph.
Simulate a clinical trial from this model, with 2000 participants in each treatment arm. Assume that the age distribution for those volunteering for the trial has a mean of 70 and a standard deviation of 8.
Code
simdat <-function(n, mage, sdage=8, fem=0.5, a =0,b1 =log(2), b2 =0.01, b3 =0.07, b4 =0.5) { age <-rnorm(n, mage, sdage) sex <-sample(c('female', 'male'), n, replace=TRUE, prob=c(fem, 1.- fem)) tx <-c(rep('A', n/2), rep('B', n/2)) logit <- a + b1 * (tx =='B') + b2 * age + b3 *pmax(age -65, 0) + b4 * (sex =='male') prob <-plogis(logit) y <-ifelse(runif(n) <= prob, 1, 0)data.frame(age, sex, tx, y)}set.seed(1)d <-simdat(n=4000, mage=70)dd <-datadist(d); options(datadist='dd')
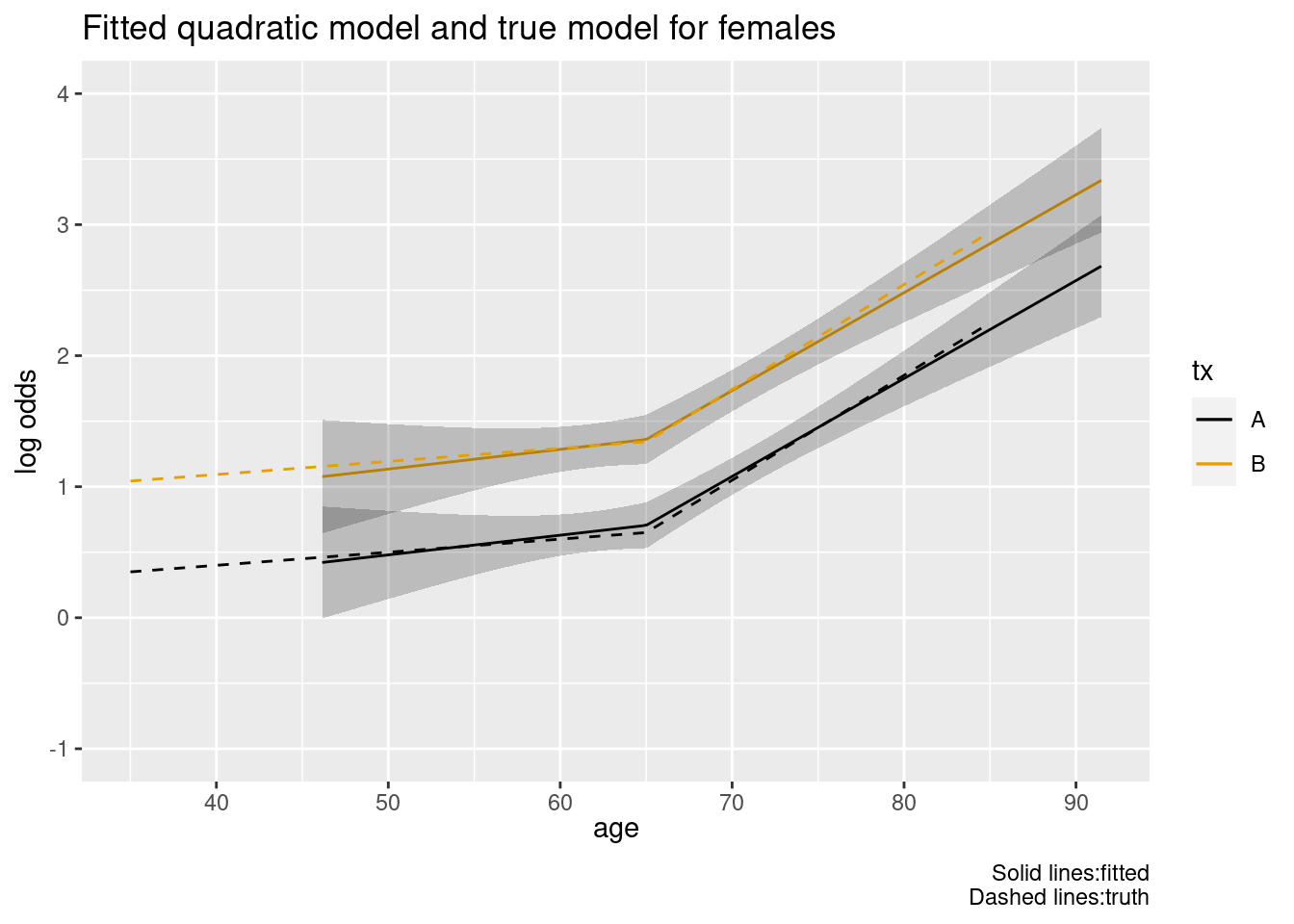
First fit the correct structure—a linear spline in age and with the sex variable included—to make sure we can approximately recover the truth with this fairly large sample size.
Code
f <-lrm(y ~ tx +lsp(age, 65) + sex, data=d)f
Logistic Regression Model
lrm(formula = y ~ tx + lsp(age, 65) + sex, data = d)
Model Likelihood Ratio Test
Discrimination Indexes
Rank Discrim. Indexes
Obs 4000
LR χ2 196.93
R2 0.080
C 0.664
0 676
d.f. 4
R24,4000 0.047
Dxy 0.329
1 3324
Pr(>χ2) <0.0001
R24,1685.3 0.108
γ 0.329
max |∂log L/∂β| 4×10-12
Brier 0.134
τa 0.092
β
S.E.
Wald Z
Pr(>|Z|)
Intercept
-0.2723
0.8159
-0.33
0.7385
tx=B
0.6550
0.0885
7.41
<0.0001
age
0.0150
0.0132
1.14
0.2539
age’
0.0597
0.0190
3.15
0.0016
sex=male
0.4661
0.0875
5.33
<0.0001
Code
ggplot(Predict(f, age, tx, sex='female')) +geom_line(data=wf, aes(x=age, y=xb, color=tx, linetype=I(2))) +labs(title="Fitted quadratic model and true model for females",caption="Solid lines:fitted\nDashed lines:truth")
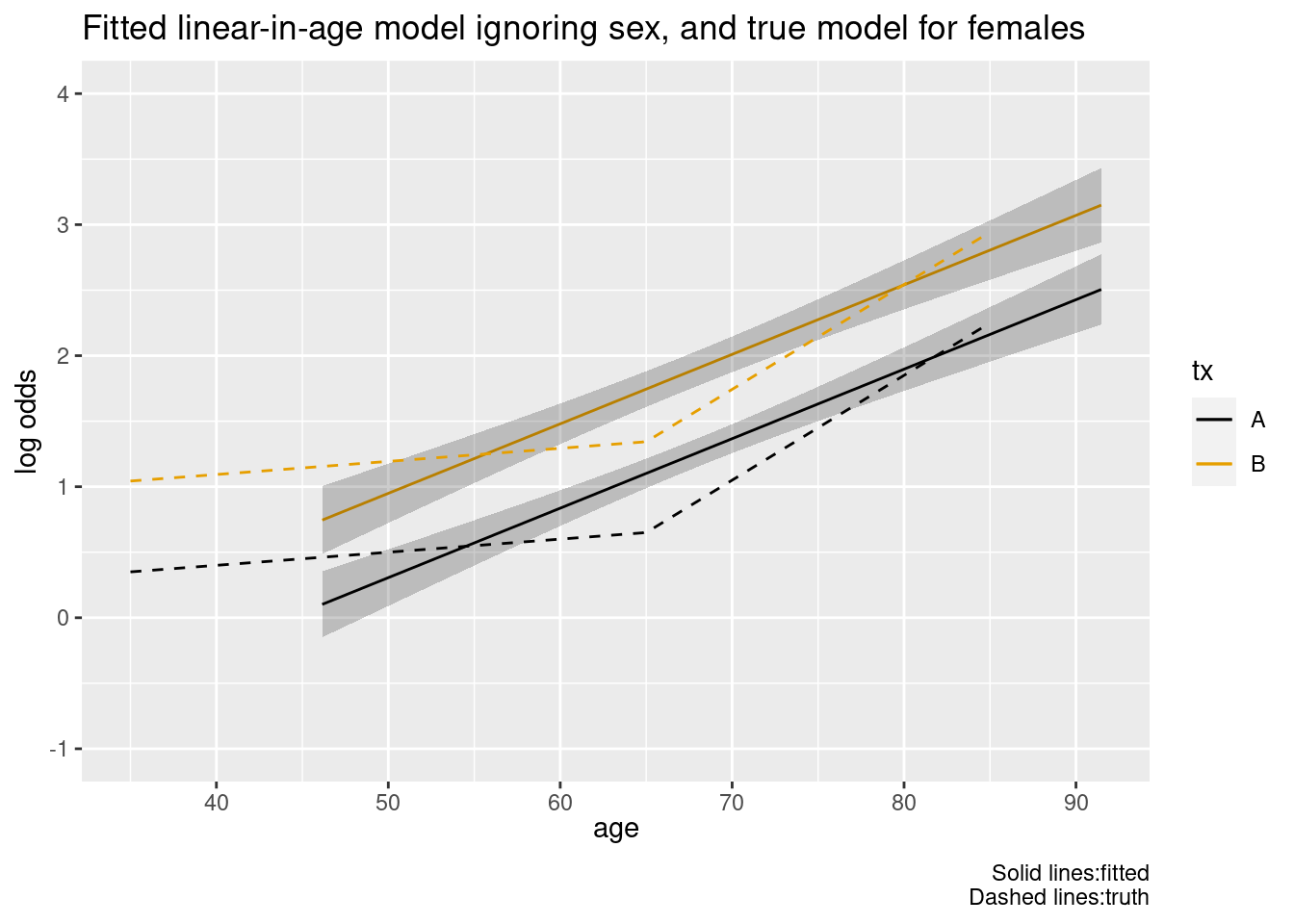
Now fit the incorrect model that assumes age is linear and omits sex. Also compute Huber-White robust variance-covariance estimates.
Code
g <-lrm(y ~ tx + age, data=d, x=TRUE, y=TRUE)g
Logistic Regression Model
lrm(formula = y ~ tx + age, data = d, x = TRUE, y = TRUE)
Model Likelihood Ratio Test
Discrimination Indexes
Rank Discrim. Indexes
Obs 4000
LR χ2 158.98
R2 0.065
C 0.649
0 676
d.f. 2
R22,4000 0.038
Dxy 0.299
1 3324
Pr(>χ2) <0.0001
R22,1685.3 0.089
γ 0.299
max |∂log L/∂β| 5×10-7
Brier 0.135
τa 0.084
β
S.E.
Wald Z
Pr(>|Z|)
Intercept
-2.3459
0.3657
-6.41
<0.0001
tx=B
0.6434
0.0881
7.31
<0.0001
age
0.0530
0.0053
9.96
<0.0001
Code
ggplot(Predict(g, age, tx)) +geom_line(data=wf, aes(x=age, y=xb, color=tx, linetype=I(2))) +labs(title="Fitted linear-in-age model ignoring sex, and true model for females",caption="Solid lines:fitted\nDashed lines:truth")
Code
rob <-robcov(g)rob
Logistic Regression Model
lrm(formula = y ~ tx + age, data = d, x = TRUE, y = TRUE)
Model Likelihood Ratio Test
Discrimination Indexes
Rank Discrim. Indexes
Obs 4000
LR χ2 158.98
R2 0.065
C 0.649
0 676
d.f. 2
R22,4000 0.038
Dxy 0.299
1 3324
Pr(>χ2) <0.0001
R22,1685.3 0.089
γ 0.299
max |∂log L/∂β| 5×10-7
Brier 0.135
τa 0.084
β
S.E.
Wald Z
Pr(>|Z|)
Intercept
-2.3459
0.3524
-6.66
<0.0001
tx=B
0.6434
0.0882
7.29
<0.0001
age
0.0530
0.0051
10.37
<0.0001
The poorly fitting model profited from balanced in the (unknown to it) sex distribution. The robust standard error estimates did not change the (improperly chosen) model-based standard errors very much in this instance.
Now fit an unadjusted model.
Code
h <-lrm(y ~ tx, data=d)h
Logistic Regression Model
lrm(formula = y ~ tx, data = d)
Model Likelihood Ratio Test
Discrimination Indexes
Rank Discrim. Indexes
Obs 4000
LR χ2 55.68
R2 0.023
C 0.578
0 676
d.f. 1
R21,4000 0.014
Dxy 0.157
1 3324
Pr(>χ2) <0.0001
R21,1685.3 0.032
γ 0.309
max |∂log L/∂β| 2×10-12
Brier 0.139
τa 0.044
β
S.E.
Wald Z
Pr(>|Z|)
Intercept
1.3069
0.0546
23.93
<0.0001
tx=B
0.6390
0.0869
7.35
<0.0001
Treatment effect estimates and SEs are summarized below.
Model
\(\hat{\beta}_{1}\)
SE
OR
Correct
0.66
0.09
1.92
Linear
0.64
0.09
1.90
Unadjusted
0.64
0.09
1.89
The difference between fitting the correct and the incorrect models usually results in larger changes in treatment effect estimates and/or standard errors than what we see here, but the main points of this exercise are (1) how far the unadjusted treatment effect estimate is from the true value used in data generation, and (2) the difficulty in interpreting marginal estimates.
Adjusted Marginal Estimates
The crude marginal proportions of Y=1 stratified by treatment A, B are 0.787 and 0.875. A slight simplification of the Benkeser estimate (we are not fitting separate models for treatments A and B) is computed below.
Code
marg <-function(fit, data, sx=FALSE) { prop <-with(data, tapply(y, tx, mean))# Compute estimated P(Y=1) as if everyone was on treatment A da <-data.frame(tx='A', age=data$age)if(sx) da$sex <- data$sex pa <-plogis(predict(fit, da))# Compute the same as if everyone was on treatment B db <-data.frame(tx='B', age=data$age)if(sx) db$sex <- data$sex pb <-plogis(predict(fit, db)) odds <-function(x) x / (1.- x) ma <-mean(pa); mb <-mean(pb) z <-rbind('Marginal covariate adjusted'=c(ma, mb, mb - ma, odds(mb)/odds(ma)),'Observed proportions'=c(prop, prop[2] - prop[1], odds(prop[2])/odds(prop[1])))colnames(z) <-c('A', 'B', 'B - A', 'OR')round(z, 3)}marg(g, d)
A B B - A OR
Marginal covariate adjusted 0.788 0.874 0.086 1.871
Observed proportions 0.787 0.875 0.088 1.895
In this instance, the marginal B:A odds ratio happened to almost equal the true conditional OR, which will not be the case in general. For comparison, compute marginal estimates for the correctly fitted model.
Code
marg(f, d, sx=TRUE)
A B B - A OR
Marginal covariate adjusted 0.788 0.875 0.087 1.883
Observed proportions 0.787 0.875 0.088 1.895
The marginal estimates are very close to the raw proportions (this will not be true in general), but as Benkeser et al discussed, they always have an advantage over crude estimates in that their standard errors are smaller. Estimates from the incorrect covariate model are virtually the same as from the correct model.
The question now is how to interpret the 0.087 estimated marginal difference in P(Y=1) between treatments. This difference is a function of all of the values of age observed in the data. It is specific to the participants volunteering to be in our simulated clinical trial. Without selecting a probability sample from the population (i.e., without relying on volunteerism), we have no way to weight the individual P(Y=1) estimates to the population.
How does the marginal difference apply to a clinical population in which the age distribution has a mean that is 15 years younger than the volunteers from which our trial participants were drawn and that instead of a 50:50 sex distribution has 0.65 females? We simulate such a sample.
A B B - A OR
Marginal covariate adjusted 0.678 0.807 0.13 1.996
Observed proportions 0.677 0.807 0.13 1.997
Code
marg(f, d, sx=TRUE)
A B B - A OR
Marginal covariate adjusted 0.676 0.808 0.132 2.019
Observed proportions 0.677 0.807 0.130 1.997
Traditional covariate adjustment with a misspecified model managed to correctly estimate the treatment effect:
Code
lrm(y ~ tx + age, data=d)
Logistic Regression Model
lrm(formula = y ~ tx + age, data = d)
Model Likelihood Ratio Test
Discrimination Indexes
Rank Discrim. Indexes
Obs 4000
LR χ2 97.22
R2 0.035
C 0.597
0 1030
d.f. 2
R22,4000 0.024
Dxy 0.194
1 2970
Pr(>χ2) <0.0001
R22,2294.3 0.041
γ 0.194
max |∂log L/∂β| 2×10-11
Brier 0.187
τa 0.074
β
S.E.
Wald Z
Pr(>|Z|)
Intercept
0.0270
0.2558
0.11
0.9160
tx=B
0.6926
0.0743
9.32
<0.0001
age
0.0130
0.0046
2.84
0.0045
Code
lrm(y ~ tx + age + sex, data=d)
Logistic Regression Model
lrm(formula = y ~ tx + age + sex, data = d)
Model Likelihood Ratio Test
Discrimination Indexes
Rank Discrim. Indexes
Obs 4000
LR χ2 150.88
R2 0.054
C 0.623
0 1030
d.f. 3
R23,4000 0.036
Dxy 0.246
1 2970
Pr(>χ2) <0.0001
R23,2294.3 0.062
γ 0.246
max |∂log L/∂β| 5×10-9
Brier 0.184
τa 0.094
β
S.E.
Wald Z
Pr(>|Z|)
Intercept
-0.1607
0.2586
-0.62
0.5343
tx=B
0.7128
0.0749
9.52
<0.0001
age
0.0128
0.0046
2.79
0.0053
sex=male
0.5809
0.0811
7.16
<0.0001
Code
lrm(y ~ tx +lsp(age, 65) + sex, data=d)
Logistic Regression Model
lrm(formula = y ~ tx + lsp(age, 65) + sex, data = d)
Model Likelihood Ratio Test
Discrimination Indexes
Rank Discrim. Indexes
Obs 4000
LR χ2 162.36
R2 0.058
C 0.624
0 1030
d.f. 4
R24,4000 0.039
Dxy 0.247
1 2970
Pr(>χ2) <0.0001
R24,2294.3 0.067
γ 0.248
max |∂log L/∂β| 2×10-5
Brier 0.184
τa 0.095
β
S.E.
Wald Z
Pr(>|Z|)
Intercept
0.3295
0.2996
1.10
0.2714
tx=B
0.7148
0.0749
9.54
<0.0001
age
0.0032
0.0055
0.58
0.5587
age’
0.1040
0.0328
3.17
0.0015
sex=male
0.5824
0.0812
7.17
<0.0001
Now instead of an increase in the probability of Y=1 due to treatment B in the mean age 70 group of 0.086 we have an increase of 0.130 in the younger and more female general clinical population that has lower risk. The 0.086 estimate no longer applies.
Frequentist Operating Characteristics
Type I
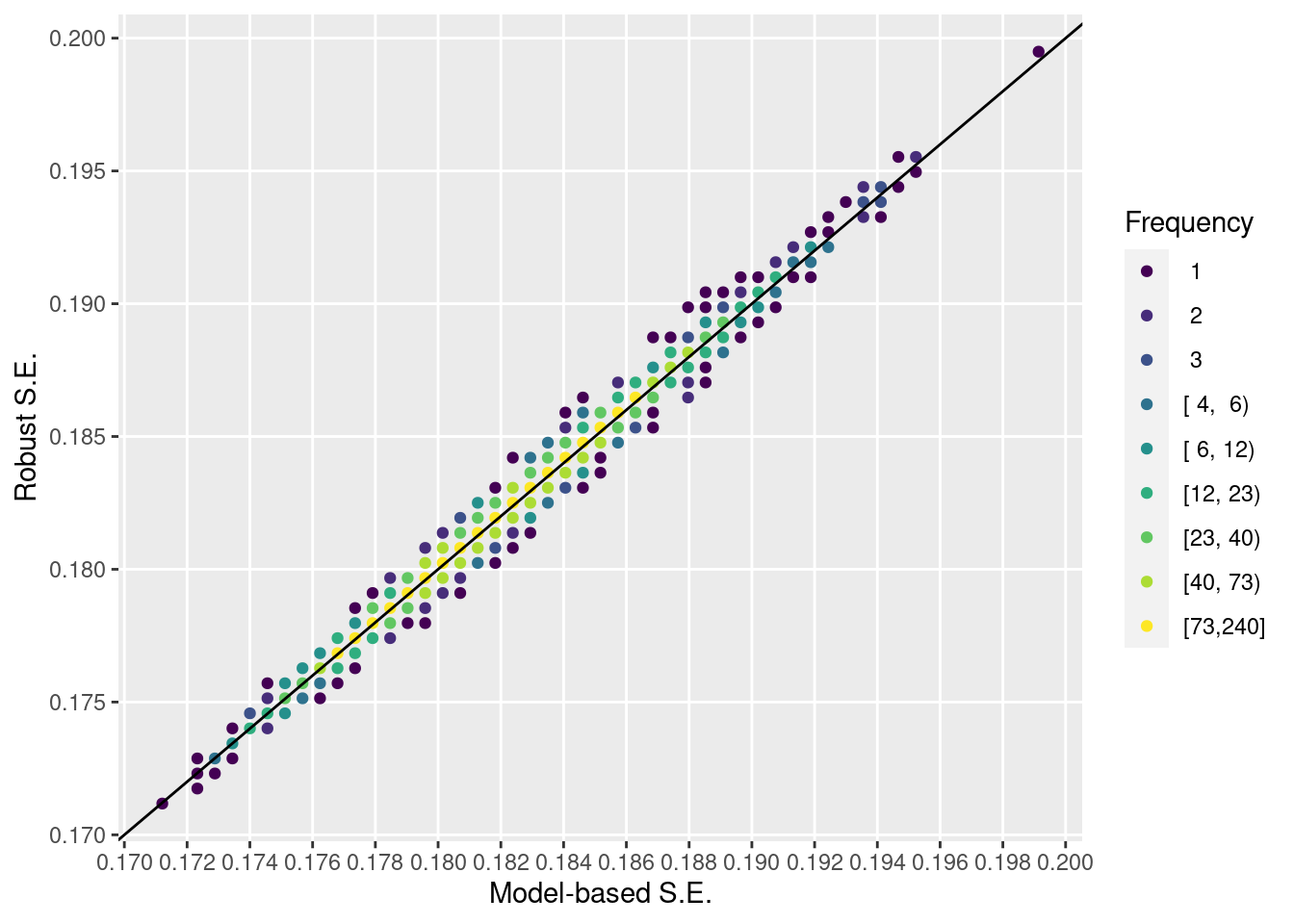
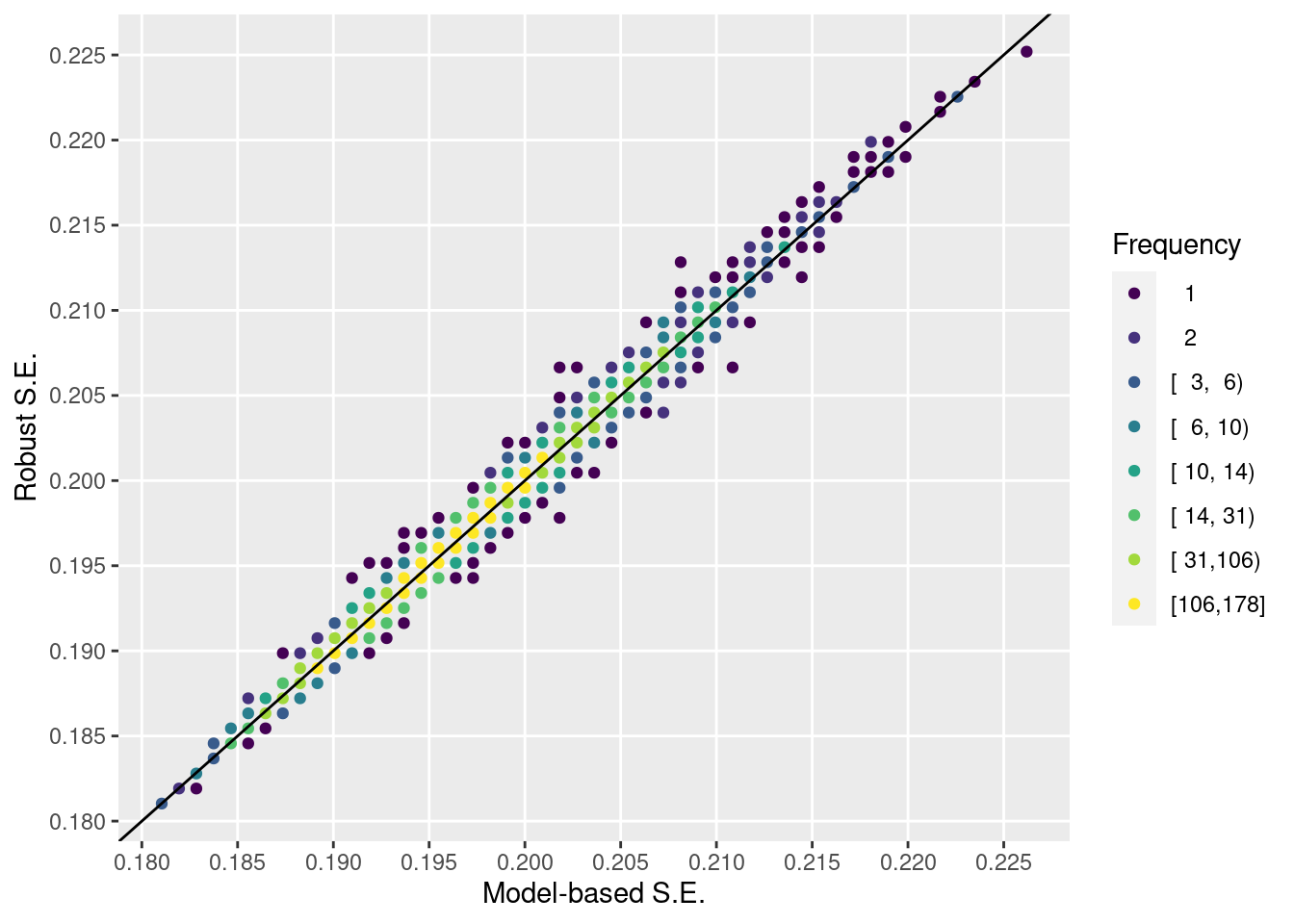
One may worry that the parametric model that falsely assumed linear age and zero sex effects has poor frequentist operating characteristics. Let’s explore the type I assertion probability \(\alpha\) of the linear-in-age logistic model omitting sex, by simulating 5000 trials just like our original trial but with a zero age and sex-conditional treatment effect. We consider the ordinary Wald statistic for treatment, and the Huber-White robust Wald statistic. Instead of using sample sizes of 4000 we use 600. Also compute \(\alpha\) using the actual standard errors for the logistic model, and run the likelihood ratio \(\chi^2\) test for treatment based on the incorrect model. Compute \(\alpha\) for the marginal adjusted effect test assuming normality and by using the true standard error (to within simulation error, that is).
SE Power
Usual LRM 0.182 0.045
Robust SE 0.182 0.045
Actual SE 0.180 0.048
Correct model, usual 0.183 0.046
Incorrect model, LR NA 0.047
Marginal 0.036 0.049
Model-based treatment effect standard errors are indistinguishable from robust standard errors in this example. For both types of Wald statistics for testing the treatment effect, \(\alpha\) was estimated to be very slightly below the nominal 0.05 level. The significant lack of fit caused by assuming that (1) a very strong covariate (age) is linear and (2) the sex effect is zero did not harm the frequentist assertion probability under the null. The adjusted marginal method had an accurate \(\alpha\), at least when the standard error did not need to be estimated from the data.
Type II
Now consider power to detect a treatment OR of 1.75 for n=600. Give the adjusted marginal method the benefit of not having to estimate the standard error of the difference in average probabilities, by using the standard deviation of observed point estimates over the simulation. For ordinary logistic covariate adjustment we include both the correct and the incorrect models. For the marginal method the incorrect model is used.
Code
set.seed(8)simoc(b1=log(1.75))
SE Power
Usual LRM 0.197 0.808
Robust SE 0.197 0.809
Actual SE 0.200 0.794
Correct model, usual 0.202 0.813
Incorrect model, LR NA 0.812
Marginal 0.035 0.809
Ordinary covariate adjustment resulted in slightly better power (0.813 vs. 0.808) when the correct model was used. The power of the adjusted marginal comparison (0.809) was virtually the same as these, when the standard error did not need to be estimated.
Conclusion
The marginal treatment effect estimate involves averaging of unlikes. Even though outcome heterogeneity is taken into account, the averaging at the final step hides the outcome heterogeneity that dictates that the risks of outcomes vary systematically by strong baseline covariates. This makes the marginal estimate sample-specific, difficult to interpret, and prevents it from applying to target populations. And critics of traditional covariate conditional models focus on possible non-robustness of nonlinear regression models. As exemplified in simulations shown here, such criticisms may be unwarranted.
If our simulation results hold more generally, the issue with adjusted marginal estimates is more with estimating magnitudes of treatment effectiveness than with statistical power. But ordinary covariate adjustment with ill-fitting nonlinear models may be just as powerful as the two-stage robust marginal procedure, while controlling \(\alpha\).
Risk differences are clinically relevant measures of treatment effect. But because of extreme baseline risk-dependent heterogeneity of risk differences, risk differences should be covariate-specific and not averaged. This is discussed in more detail here.
---title: Incorrect Covariate Adjustment May Be More Correct than Adjusted Marginal Estimatesauthor: - name: Frank Harrell url: https://hbiostat.org affiliation: Vanderbilt University<br>School of Medicine<br>Department of Biostatisticsdate: 2021-06-29modified: 2022-09-25categories: [2021, generalizability, RCT, regression]description: "This article provides a demonstration that the perceived non-robustness of nonlinear models for covariate adjustment in randomized trials may be less of an issue than the non-transportability of marginal so-called robust estimators."---```{r setup, include=FALSE}require(rms)require(knitr)require(ggplot2)options(prType='html')```<style>.table {width:50%;}</style>::: {.quoteit}We usually treat individuals not populations. That being so, rational decision-making involves considering who to treat not whether the population as a whole should be treated. I think there are few exceptions to this. One I can think of is water-fluoridation but in most cases we should be making decisions about individuals. In short, there may be reasons on occasion to use marginal models but treating populations will rarely be one of them. — Stephen Senn, 2022:::# Background In a randomized clinical trial (RCT) it is typical for several participants' baseline characteristics to be much more predictive of the outcome variable Y than treatment is predictive of Y. Covariate adjustment in an RCT gains power by making the analysis more consistent with the data generating model, i.e., by accounting for outcome heterogeneity due to wide distributions of baseline prognostic factors. When Y is continuous and random errors have a normal distribution, it is well known that classical covariate adjustment improves power over an unadjusted analysis no matter how poorly the model fits. Lack of fit makes the random errors larger, but not as large as omitting covariates entirely. Nonlinear models such as logistic or Cox regression have no error term to absorb lack of fit, so lack of fit changes (usually towards zero) parameter estimates for all terms in the model, including the treatment effect. But the most poorly specified model is one that assumes all covariate effects are nil, i.e., one that does not adjust for covariates. Even ill-fitting models will provide more useful treatment effect estimates than a model that ignores covariates. See [this](https://hbiostat.org/bbr/ancova.html) for details and references about covariate adjustment in RCTs. [[Comments](https://hbiostat.org/comment.html)]{.aside}Because they are more easily connected to causal inference, many statisticians and epidemiologists like marginal effect estimates. Adjusted marginal effects can adjust for covariate imbalance and can take covariate distributions and resulting outcome heterogeneity into account, at least until the very last step that involves averaging over the covariate distribution. Adjusted marginal estimation does take outcome heterogeneity fully into account at all times when estimating variances. The following simple example for a single treatment arm study shows how that works.Suppose that a sample of 100 subjects had 40 females and 60 males, and that 10 of the females and 30 of the males had disease. The marginal estimate of the probability of disease is 40/100 = 0.4, and the variance of the estimator assuming constant risk (i.e., assuming risk for females = risk for males) is $\frac{0.4\times 0.6}{100} = 0.0024$. But with knowledge of each person's sex we compute the variance using sex-specific risk estimates as follows. The marginal estimate combines the sex-specific estimates according to the sex distribution in the sample (a hint that what is about to happen doesn't apply to the population). This estimate is $0.4 \times 0.25 + 0.6 \times 0.5 = 0.4$, identical to the marginal estimate. But the true and estimated variances are not the same as that computed in the absence of knowledge of subjects' sex. The estimated variance is $0.4^{2}\times \frac{0.25 \times 0.75}{40} + 0.6^{2}\times \frac{0.5 \times 0.5}{60} = 0.00225$ which is smaller than 0.0024 due to the fact that the correct variance recognizes that males and females do not have the same outcome probabilities. So marginal stratified/adjusted estimation corrects the mistake of using the wrong variance formulas when computing crude marginal estimates, among other benefits such as preventing Simpson's "paradox". Any time you see $\frac{p \times (1-p)}{n}$ for the variance of a proportion, remember that this formula assumes that $p$ applies equally to all $n$ subjects.Turning to the more interesting two-sample problem, the adjusted marginal approach can be used to derive other interesting quantities such as marginal adjusted hazard or odds ratios. As opposed to estimating relative treatment effect conditional on covariate values, marginal estimands that account for covariates (outcome heterogeneity) are based on differences in average predicted values. Advocates of marginal treatment effect estimates for nonlinear models such as [Benkeser, Díaz, Luedtke, Segal, Scharfstein, and Rosenblum](https://pubmed.ncbi.nlm.nih.gov/32978962)[^ben] cite as one of the main advantages of the method its robustness to model misspecification. In their approach, gains in efficiency from covariate adjustment can result, and certain types of model lack of fit are in effect averaged out. But it is this averaging that makes the resulting treatment effect in an RCT hard to interpret. Their marginal treatment effect uses a regression model as a stepping stone to an effect estimator in which estimates are made on a probability scale and averaged. For example, if Y is binary, one might fit a binary logistic regression model on the baseline covariates and the treatment variable (Benkeser et al. prefer to fit separate models by treatment, omitting the treatment indicator from each.) Then for every trial participant one obtains, for example, the estimated probability that Y=1 under treatment A, then for the same covariate values, the probability that Y=1 under treatment B. The estimates are averaged over all subjects and then subtracted to arrive at a marginal treatment effect estimate.There are problems with this approach:* it changes the estimand to something that is not applicable to individual patient decision making* it estimates the difference in probabilities over the distribution of _observed covariate values_ and is dependent on the covariate distributions of participants actually entering the trial * this fails to recognize that RCT participants are not a random sample from the target population; RCTs are valid when their designs result in representative _treatment effects_, and they do not require representative _participants_ * to convert marginal estimates to estimates that are applicable to the population requires the RCT sample to be a probability sample and for the sampling probabilities from the population to be known* these sampling weights are almost never known; RCTs are almost always based on convenience samples* the marginal approach makes assessment of differential treatment effect (interactions) difficultThe claim that ordinary conditional estimates are not robust also needs further exploration. Here I take a simple example where there are two strong covariates---age and sex---and age has a very nonlinear true effect on the log odds that Y=1. Suppose that the investigators do not know much about flexible parametric modeling (the use of regression splines, etc.) but assume that age has a linear effect, and does the covariate adjustment assuming linearity. Suppose also that sex is omitted from the model. What happens? Is the resulting conditional odds ratio (OR) for treatment valid? We will see that it is not exactly correct, but that it can be more valid than the marginal estimate. In regression analysis one can never get the model "correct." Instead, modeling is a question of approximating the effects of baseline variables that explain outcome heterogeneity. The better the model the more complete the conditioning and the more accurate the patient-specific effects that are estimated from the model. Omitted covariates or under-fitting strong nonlinear relationships results in effectively conditioning on only part of what one would like to know. This partial conditioning still results in useful estimates, and the estimated treatment effect will be somewhere between a fully correctly adjusted effect and a non-covariate-adjusted effect.# Simulation ModelAssume a true model as specified below:$$\Pr(Y = 1 | T,A,S) = \mathrm{expit}(\alpha + \beta_{1} [T=B] + \beta_{2} A + \beta_{3} (A - 65)_{+} + \\ \beta_{4} [S=\mathrm{male}])$$where $A$ is age, treatment $T$ is A or B, $S$ is sex, and $\mathrm{expit}$ denotes the inverse of the logit function, i.e., $\frac{1}{1 + \exp(-u)}$. $u_{+}$ is defined as $u$ if $u > 0$ and 0 otherwise, and $[u]$ is 1 if $u$ is true and 0 otherwise. We assume the effect of using treatment B instead of treatment A raises the odds that Y=1 by a factor of 2.0, i.e., the treatment effect is OR=2 so that $\beta_{1}=\log(2)=0.6931$. The age effect is a linear spline with slope change at 65y. Assume the true age effect is given by the initial slope of $\beta_{2}=0.01$ and the increment in slope starting at age 65 is $\beta_{3}=0.07$. Assume that $\beta_{4}=0.5$ and $\alpha=0$. Then the true relationships are given in the following graph.```{r truemod}a <-0; b1 <-log(2); b2 <-0.01; b3 <-0.07; b4 <-0.5w <-expand.grid(age=seq(35, 85, length=100), sex=c('female', 'male'), tx=c('A','B'))w <-transform(w, xb=a + b1 * (tx =='B') + b2 * age + b3 *pmax(age -65, 0) + b4 * (sex =='male'))wf <-subset(w, sex=='female')ggplot(w, aes(x=age, y=xb, color=tx, linetype=sex)) +geom_line() +ylab('logit')```Simulate a clinical trial from this model, with 2000 participants in each treatment arm. Assume that the age distribution for those volunteering for the trial has a mean of 70 and a standard deviation of 8.```{r simdata}simdat <-function(n, mage, sdage=8, fem=0.5, a =0,b1 =log(2), b2 =0.01, b3 =0.07, b4 =0.5) { age <-rnorm(n, mage, sdage) sex <-sample(c('female', 'male'), n, replace=TRUE, prob=c(fem, 1.- fem)) tx <-c(rep('A', n/2), rep('B', n/2)) logit <- a + b1 * (tx =='B') + b2 * age + b3 *pmax(age -65, 0) + b4 * (sex =='male') prob <-plogis(logit) y <-ifelse(runif(n) <= prob, 1, 0)data.frame(age, sex, tx, y)}set.seed(1)d <-simdat(n=4000, mage=70)dd <-datadist(d); options(datadist='dd')```First fit the correct structure---a linear spline in age and with the sex variable included---to make sure we can approximately recover the truth with this fairly large sample size.```{r fittrue,results='asis'}f <-lrm(y ~ tx +lsp(age, 65) + sex, data=d)fggplot(Predict(f, age, tx, sex='female')) +geom_line(data=wf, aes(x=age, y=xb, color=tx, linetype=I(2))) +labs(title="Fitted quadratic model and true model for females",caption="Solid lines:fitted\nDashed lines:truth")```Now fit the incorrect model that assumes age is linear and omits sex. Also compute Huber-White robust variance-covariance estimates.```{r fitlin,results='asis'}g <-lrm(y ~ tx + age, data=d, x=TRUE, y=TRUE)gggplot(Predict(g, age, tx)) +geom_line(data=wf, aes(x=age, y=xb, color=tx, linetype=I(2))) +labs(title="Fitted linear-in-age model ignoring sex, and true model for females",caption="Solid lines:fitted\nDashed lines:truth")rob <-robcov(g)rob```The poorly fitting model profited from balanced in the (unknown to it) sex distribution.The robust standard error estimates did not change the (improperly chosen) model-based standard errors very much in this instance.Now fit an unadjusted model.```{r unadj,results='asis'}h <-lrm(y ~ tx, data=d)h```Treatment effect estimates and SEs are summarized below.| Model | $\hat{\beta}_{1}$ | SE | OR ||-------|-------------|----|------||Correct | 0.66 | 0.09 | 1.92 ||Linear | 0.64 | 0.09 | 1.90 ||Unadjusted| 0.64 | 0.09 | 1.89 |The difference between fitting the correct and the incorrect models usually results in larger changes in treatment effect estimates and/or standard errors than what we see here, but the main points of this exercise are (1) how far the unadjusted treatment effect estimate is from the true value used in data generation, and (2) the difficulty in interpreting marginal estimates.# Adjusted Marginal EstimatesThe crude marginal proportions of Y=1 stratified by treatment A, B are `r with(d, paste(tapply(y, tx, mean), collapse=' and '))`. A slight simplification of the Benkeser estimate (we are not fitting separate models for treatments A and B) is computed below.```{r marg}marg <-function(fit, data, sx=FALSE) { prop <-with(data, tapply(y, tx, mean))# Compute estimated P(Y=1) as if everyone was on treatment A da <-data.frame(tx='A', age=data$age)if(sx) da$sex <- data$sex pa <-plogis(predict(fit, da))# Compute the same as if everyone was on treatment B db <-data.frame(tx='B', age=data$age)if(sx) db$sex <- data$sex pb <-plogis(predict(fit, db)) odds <-function(x) x / (1.- x) ma <-mean(pa); mb <-mean(pb) z <-rbind('Marginal covariate adjusted'=c(ma, mb, mb - ma, odds(mb)/odds(ma)),'Observed proportions'=c(prop, prop[2] - prop[1], odds(prop[2])/odds(prop[1])))colnames(z) <-c('A', 'B', 'B - A', 'OR')round(z, 3)}marg(g, d)```In this instance, the marginal B:A odds ratio happened to almost equal the true conditional OR, which will not be the case in general. For comparison, compute marginal estimates for the correctly fitted model.```{r margc}marg(f, d, sx=TRUE)```The marginal estimates are very close to the raw proportions (this will not be true in general), but as Benkeser et al discussed, they always have an advantage over crude estimates in that their standard errors are smaller. Estimates from the incorrect covariate model are virtually the same as from the correct model.The question now is how to interpret the 0.087 estimated marginal difference in P(Y=1) between treatments. This difference is a function of all of the values of age observed in the data. It is specific to the participants volunteering to be in our simulated clinical trial. Without selecting a probability sample from the population (i.e., without relying on volunteerism), we have no way to weight the individual P(Y=1) estimates to the population.How does the marginal difference apply to a clinical population in which the age distribution has a mean that is 15 years younger than the volunteers from which our trial participants were drawn and that instead of a 50:50 sex distribution has 0.65 females? We simulate such a sample.```{r simnew}set.seed(2)d <-simdat(4000, mage=55, fem=0.65)f <-lrm(y ~ tx +lsp(age, 65) + sex, data=d)g <-lrm(y ~ tx + age, data=d)marg(g, d)marg(f, d, sx=TRUE)```Traditional covariate adjustment with a misspecified model managed to correctly estimate the treatment effect:```{r simnewlr,results='asis'}lrm(y ~ tx + age, data=d)lrm(y ~ tx + age + sex, data=d)lrm(y ~ tx +lsp(age, 65) + sex, data=d)```Now instead of an increase in the probability of Y=1 due to treatment B in the mean age 70 group of 0.086 we have an increase of 0.130 in the younger and more female general clinical population that has lower risk. The 0.086 estimate no longer applies.# Frequentist Operating Characteristics## Type IOne may worry that the parametric model that falsely assumed linear age and zero sex effects has poor frequentist operating characteristics. Let's explore the type I assertion probability $\alpha$ of the linear-in-age logistic model omitting sex, by simulating 5000 trials just like our original trial but with a zero age and sex-conditional treatment effect. We consider the ordinary Wald statistic for treatment, and the Huber-White robust Wald statistic. Instead of using sample sizes of 4000 we use 600. Also compute $\alpha$ using the actual standard errors for the logistic model, and run the likelihood ratio $\chi^2$ test for treatment based on the incorrect model. Compute $\alpha$ for the marginal adjusted effect test assuming normality and by using the true standard error (to within simulation error, that is).```{r simalpha}simoc <-function(m=5000, b1=0., n=600) { beta <- betac <- v1 <- v2 <- vc <- margdiff <- lr <-numeric(m) w <-'tx=B'for(i in1: m) { d <-simdat(n, mage=60, b1=b1) f <-lrm(y ~ tx + age, data=d, x=TRUE, y=TRUE) g <-robcov(f) h <-lrm(y ~ tx +lsp(age, 65) + sex, data=d) u <-lrm(y ~ age, data=d) beta[i] <-coef(f)[w] v1[i] <-vcov(f)[w, w] v2[i] <-vcov(g)[w, w] betac[i] <-coef(h)[w] vc[i] <-vcov(h)[w, w] margdiff[i] <-marg(f, d)[1, 'B - A'] lr[i] <-lrtest(u, f)$stats['L.R. Chisq'] }print(ggfreqScatter(sqrt(v1), sqrt(v2)) +geom_abline(slope=1, intercept=0) +xlab('Model-based S.E.') +ylab('Robust S.E.')) pow <-function(beta, v) mean(abs(beta /sqrt(v)) >qnorm(0.975)) r <-rbind('Usual LRM'=c(SE=sqrt(mean(v1)), Power=pow(beta, v1)),'Robust SE'=c(SE=sqrt(mean(v2)), Power=pow(beta, v2)),'Actual SE'=c(SE=sd(beta), Power=pow(beta, var(beta))),'Correct model, usual'=c(SE=sd(betac), Power=pow(betac, vc)),'Incorrect model, LR'=c(SE=NA, Power=mean(lr >qchisq(0.95, 1))),'Marginal'=c(SE=sd(margdiff), Power=pow(margdiff, var(margdiff))))round(r, 3)}set.seed(7)simoc(b1=0.)```Model-based treatment effect standard errors are indistinguishable from robust standard errors in this example. For both types of Wald statistics for testing the treatment effect, $\alpha$ was estimated to be very slightly **below** the nominal 0.05 level.The significant lack of fit caused by assuming that (1) a very strong covariate (age) is linear and (2) the sex effect is zero did not harm the frequentist assertion probability under the null. The adjusted marginal method had an accurate $\alpha$, at least when the standard error did not need to be estimated from the data.## Type IINow consider power to detect a treatment OR of 1.75 for n=600. Give the adjusted marginal method the benefit of not having to estimate the standard error of the difference in average probabilities, by using the standard deviation of observed point estimates over the simulation. For ordinary logistic covariate adjustment we include both the correct and the incorrect models. For the marginal method the incorrect model is used.```{r simbeta}set.seed(8)simoc(b1=log(1.75))```Ordinary covariate adjustment resulted in slightly better power (0.813 vs. 0.808) when the correct model was used. The power of the adjusted marginal comparison (0.809) was virtually the same as these, when the standard error did not need to be estimated.# ConclusionThe marginal treatment effect estimate involves averaging of unlikes. Even though outcome heterogeneity is taken into account, the averaging at the final step hides the outcome heterogeneity that dictates that the risks of outcomes vary systematically by strong baseline covariates. This makes the marginal estimate sample-specific, difficult to interpret, and prevents it from applying to target populations. And critics of traditional covariate conditional models focus on possible non-robustness of nonlinear regression models. As exemplified in simulations shown here, such criticisms may be unwarranted.If our simulation results hold more generally, the issue with adjusted marginal estimates is more with estimating magnitudes of treatment effectiveness than with statistical power. But ordinary covariate adjustment with ill-fitting nonlinear models may be just as powerful as the two-stage robust marginal procedure, while controlling $\alpha$.Risk differences are clinically relevant measures of treatment effect. But because of extreme baseline risk-dependent heterogeneity of risk differences, risk differences should be **covariate-specific** and not averaged. This is discussed in more detail [here](/post/rdist).# References[^ben]: Benkeser D, Díaz I, Luedtke A, Segal J, Scharfstein D, Rosenblum M (2020): Improving precision and power in randomized trials for COVID-19 treatments using covariate adjustment, for binary, ordinal, and time-to-event outcomes. To appear in _Biometrics_, DOI:10.1111/biom.13377.* [Covariate adjustment in randomised trials: canonical link functions protect against model mis-specification](https://arxiv.org/abs/2107.07278) by IR White, TP Morris, E Williamson# [Discussion Archive](disqus.pdf) (2021-2022)