Considering a simple fixed sample-size non-adaptive design in which standard frequentist inference agrees with non-informative prior-based Bayesian inference, it is argued that the implied assumption about the unknown effect made by frequentist inference (and Bayesian inference if the non-informative prior is actually used) is quite unrealistic.
Department of Biostatistics Vanderbilt University School of Medicine
Published
June 10, 2024
Modified
June 10, 2024
Background
Consider these four conditions:
There is no reliable prior information about an effect and an uninformative prior is used in the Bayesian analysis
There is only one look at the data
The look was pre-planned and not data-dependent
A one-sided assessment is of interest, so that one-tailed p-values and Bayesian posterior probabilities \(\Pr(\theta > 0 | \text{data, prior})\) are used, where \(\theta\) is the effect parameter of interest (e.g., difference in means, log effect ratio) and \(|\) means “conditional on” or “given”.
NoteOne-Sided vs. Two-Sided Assessment
A two-tailed frequentist test contains a multiplicity adjustment that is designed as if the researcher is equally interested in making a claim for harm as she is for benefit of a treatment. When comparing two-tailed tests to the usual Bayesian posterior probability that the benefit is greater than zero, Bayes’ directionality will give it an instant benefit. Quantifying evidence for either a positive or negative benefit through \(\max(\Pr(\theta > 0), \Pr(\theta < 0))\) will also give Bayes a benefit because this maximum must be \(\geq \Pr(\theta > 0)\). Bayes and frequentist two-sided assessments can be put on an equal footing by computing the posterior probability \(\Pr(|\theta| > \epsilon)\) for a certain sample-size-dependent \(\epsilon > 0\) (the posterior probability is 1.0 for \(\epsilon=0\) since we assume \(\theta\) is a continuous parameter with \(\Pr(\theta = 0) = 0)\). For simplicity in what follows I address only one-sided assessments.
If all four of the above conditions hold, then Bayesian inference about a positive effect will coincide largely with one minus a frequentist one-tailed p-value. However this way of thinking ignores the very important fact that even when there are no reliable data about the specific magnitude of treatment effect, there is always a reliable constraint on that unknown effect. For example, we know that most treatments are not curative, so it is impossible for the true treatment effect to have, for example, an odds ratio or hazard ratio of 0.0. Turning this idea around, since Bayesian and frequentist inference are “close” if an uninformative prior is used, what are the implications to frequentist inference?
Flatter and Flatter Priors
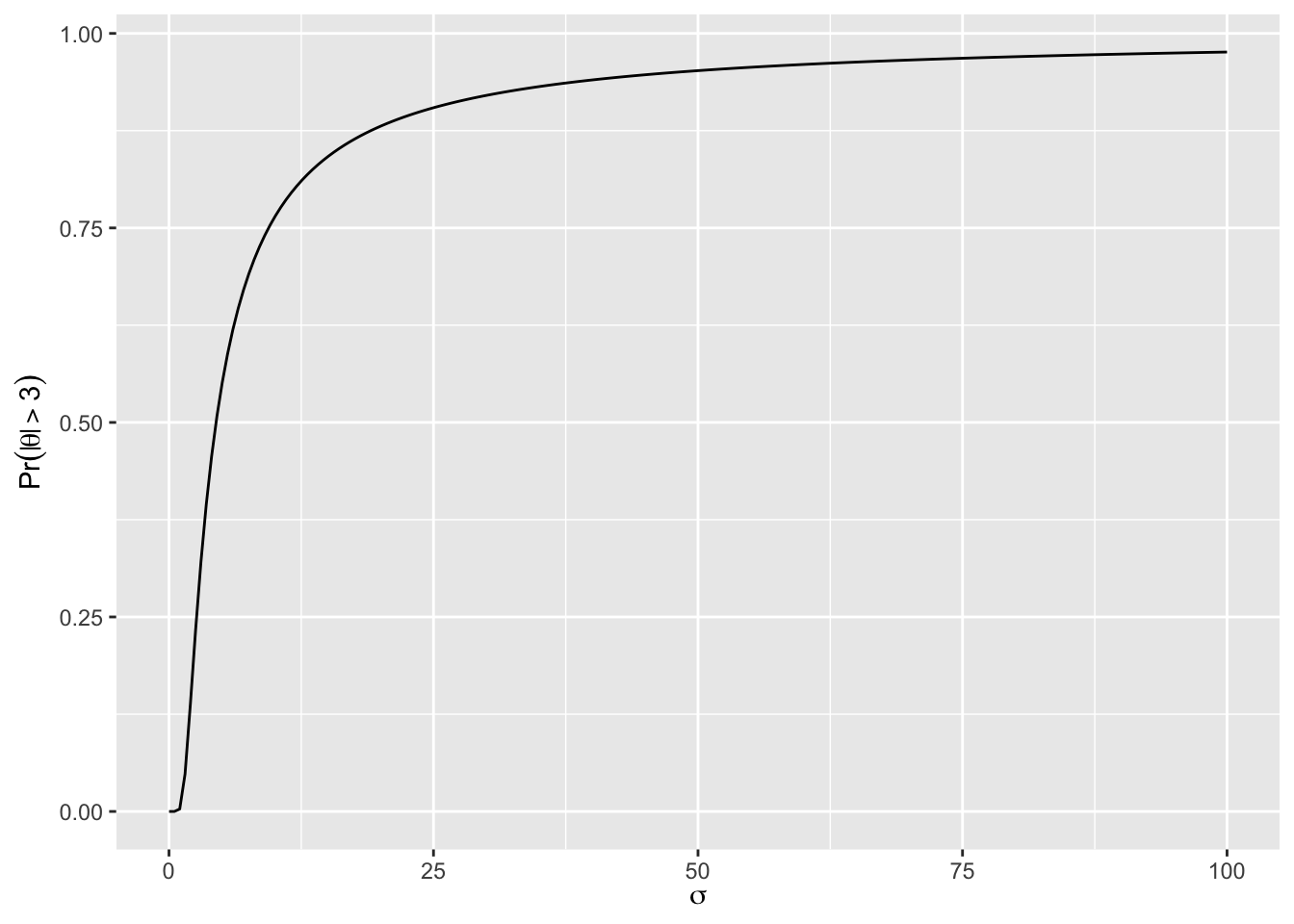
Motivated by this which contains a quote from the Prior Distributions for rstanarm Models, there are wide implications of placing no constraints on the unknown parameter \(\theta\). Before giving the implication of a truly uninformative prior on the \(\theta\) scale, consider a prior that is a Gaussian distribution with mean zero and standard deviation \(\sigma\). What does \(\sigma\) say about what we know about \(|\theta|\)?
If the raw data have a standard deviation of 1.0, a value of a difference in means of \(|\theta|\) equal to 3 would be judged to be quite large. In the vast majority of studies, there would be strong expert opinion that the chance that \(|\theta| < 3\) would exceed the chance that \(|\theta| > 3\). Let’s compute prior probabilities as a function of \(\sigma\).
When \(\sigma >\) 4.45, the probability that \(|\theta| > 3\) exceeds 0.5, i.e., the prior belief that \(|\theta| > 3\) is stronger than the belief that \(|\theta| < 3\). Is this at all reasonable?
The frequentist approach, using no information about \(\theta\), not even a restriction against never-before-seen effect sizes, effectively uses \(\sigma=\infty\), for which the prior belief that \(|\theta| > 3\) is a probability of 1.0. For the probability of the effect exceeding 3 (on a scale where a value of 1 may thought of as a large effect) to exceed the probability that the effect is between 0 and 3 is quite unrealistic is most settings.
Summary
By equating the conclusions of Bayesian and frequentist methods in a simple design with a fixed sample size and one data look, the frequentist analysis seen through a Bayesian lens favors, pre-data, impossibly large effects. Among other things, this causes, in the words of Andrew Gelman and John Carlin, type S (sign) and M (magnitude) errors.
---title: "Traditional Frequentist Inference Uses Unrealistic Priors"author: - name: Frank Harrell url: https://hbiostat.org affiliation: Department of Biostatistics<br>Vanderbilt University School of Medicinedate: 2024-06-10date-modified: last-modifiedcategories: [bayes, design, inference, hypothesis-testing, RCT, multiplicity, 2024]description: "Considering a simple fixed sample-size non-adaptive design in which standard frequentist inference agrees with non-informative prior-based Bayesian inference, it is argued that the implied assumption about the unknown effect made by frequentist inference (and Bayesian inference if the non-informative prior is actually used) is quite unrealistic."---## BackgroundConsider these four conditions:1. There is no reliable prior information about an effect and an uninformative prior is used in the Bayesian analysis1. There is only one look at the data1. The look was pre-planned and not data-dependent1. A one-sided assessment is of interest, so that one-tailed p-values and Bayesian posterior probabilities $\Pr(\theta > 0 | \text{data, prior})$ are used, where $\theta$ is the effect parameter of interest (e.g., difference in means, log effect ratio) and $|$ means "conditional on" or "given".::: {.callout-note collapse="true"}## One-Sided vs. Two-Sided AssessmentA two-tailed frequentist test contains a multiplicity adjustment that is designed as if the researcher is equally interested in making a claim for harm as she is for benefit of a treatment. When comparing two-tailed tests to the usual Bayesian posterior probability that the benefit is greater than zero, Bayes' directionality will give it an instant benefit. Quantifying evidence for either a positive or negative benefit through $\max(\Pr(\theta > 0), \Pr(\theta < 0))$ will also give Bayes a benefit because this maximum must be $\geq \Pr(\theta > 0)$. Bayes and frequentist two-sided assessments can be put on an equal footing by computing the posterior probability $\Pr(|\theta| > \epsilon)$ for a certain sample-size-dependent $\epsilon > 0$ (the posterior probability is 1.0 for $\epsilon=0$ since we assume $\theta$ is a continuous parameter with $\Pr(\theta = 0) = 0)$. For simplicity in what follows I address only one-sided assessments.:::If all four of the above conditions hold, then Bayesian inference about a positive effect will coincide largely with one minus a frequentist one-tailed p-value. However this way of thinking ignores the very important fact that even when there are no reliable data about the specific magnitude of treatment effect, there is always a reliable constraint on that unknown effect. For example, we know that most treatments are not curative, so it is impossible for the true treatment effect to have, for example, an odds ratio or hazard ratio of 0.0. Turning this idea around, since Bayesian and frequentist inference are "close" if an uninformative prior is used, what are the implications to frequentist inference?## Flatter and Flatter PriorsMotivated by [this](https://x.com/5_utr/status/1799527162283786696) which contains a quote from the [Prior Distributions for `rstanarm` Models](https://mc-stan.org/rstanarm/articles/priors.html), there are wide implications of placing no constraints on the unknown parameter $\theta$. Before giving the implication of a truly uninformative prior on the $\theta$ scale, consider a prior that is a Gaussian distribution with mean zero and standard deviation $\sigma$. What does $\sigma$ say about what we know about $|\theta|$? If the raw data have a standard deviation of 1.0, a value of a difference in means of $|\theta|$ equal to 3 would be judged to be quite large. In the vast majority of studies, there would be strong expert opinion that the chance that $|\theta| < 3$ would exceed the chance that $|\theta| > 3$. Let's compute prior probabilities as a function of $\sigma$.```{r}require(ggplot2)d <-data.frame(sigma =seq(0.01, 100, length=200))d <-transform(d, p =1-pnorm(3, 0, sigma) +pnorm(-3, 0, sigma))ggplot(d, aes(x=sigma, y=p)) +geom_line() +ylab(expression(Pr(abs(theta) >3))) +xlab(expression(sigma))sigma5 <-with(d, round(approx(p, sigma, xout=0.5)$y, 2))sigma5```When $\sigma >$ `r sigma5`, the probability that $|\theta| > 3$ exceeds 0.5, i.e., the prior belief that $|\theta| > 3$ is stronger than the belief that $|\theta| < 3$. Is this at all reasonable?The frequentist approach, using no information about $\theta$, not even a restriction against never-before-seen effect sizes, effectively uses $\sigma=\infty$, for which the prior belief that $|\theta| > 3$ is a probability of 1.0. For the probability of the effect exceeding 3 (on a scale where a value of 1 may thought of as a large effect) to exceed the probability that the effect is between 0 and 3 is quite unrealistic is most settings.## SummaryBy equating the conclusions of Bayesian and frequentist methods in a simple design with a fixed sample size and one data look, the frequentist analysis seen through a Bayesian lens favors, pre-data, impossibly large effects. Among other things, this causes, in the words of Andrew Gelman and John Carlin, [type S (sign) and M (magnitude) errors](http://www.stat.columbia.edu/~gelman/research/published/retropower20.pdf).