Since the Wilcoxon test is a special case of the proportional odds (PO) model, if one likes the Wilcoxon test, one must like the PO model. This is made more convincing by showing examples of how one may accurately compute the Wilcoxon statistic from the PO model’s odds ratio.
Vanderbilt University School of Medicine Department of Biostatistics
Published
March 10, 2021
Clearly, the dependence of the proportional odds model on the assumption of proportionality can be over-stressed. Suppose that two different statisticians would cut the same three-point scale at different cut points. It is hard to see how anybody who could accept either dichotomy could object to the compromise answer produced by the proportional odds model. — Stephen Senn
Background
The Wilcoxon-Mann-Whitney two-sample rank-sum test is a special case of the proportional odds (PO) ordinal logistic regression model. The numerator of the PO model score \(\chi^2\) test for comparing two groups without covariate adjustment is exactly the Wilcoxon statistic. The equivalence of the PO model and the Wilcoxon test in this simple two-group setting is perhaps demonstrated more compellingly by showing how the Wilcoxon test statistic may be accurately approximated by a simple function of the odds ratio (OR) estimate from the PO model, even when PO is strongly violated.
In Violation of Proportional Odds is Not Fatal I used simulation to derive an accurate approximation to the Wilcoxon statistic from the PO model group 2 : group 1 odds ratio estimate (OR). When the Wilcoxon statistic is re-scaled to have a 0-1 range, i.e., to a concordance probability\(c\), the approximation is \[c = \frac{\mathrm{OR}^{0.66}}{1 + \mathrm{OR}^{0.66}}\]
Over a wide variety of simulated datasets, this approximation has a mean absolute error of 0.0021.
1 Note that \(0.66 = \frac{1}{1.52}\) from the blog article.
For \(n\) overall observations, \(n_1\) in group 1 and \(n_2\) in group 2, let \(R\) denote the vector of ranks of all the observations ignoring group membership. In case of ties, midranks are used. The Wilcoxon rank-sum statistic \(W\) is based on the sum of ranks in group 2. Let \(X_{i}\) be [group = 2], the 1/0 indicator of being in group 2 for the \(i^{\mathrm{th}}\) observation.
Letting \(\bar{R}\) denote the mean of the group 2 ranks (\(\frac{1}{n_{2}} \sum_{i=1}^{n} X_{i}R_{i})\), the Wilcoxon statistic is proportional to
\[c = \frac{\bar{R} - \frac{n_{2} + 1}{2}}{n_{1}}\] where \(c\) is the c-index or concordance probability. It is the proportion of all possible pairs of observations, one from group 2 and one from group 1, such that the the observation from group 2 is the larger of the two. Since midranks are used for ties, \(c\) counts a tied pair as \(\frac{1}{2}\) concordant. So letting \(Y_{1}\) and \(Y_{2}\) represent, respectively, random observations from groups 1 and 2, \(c\) estimates \(\Pr(Y_{2} > Y_{1}) + \frac{1}{2} \Pr(Y_{2} = Y_{1})\).
There is an identity with Somers’ \(D_{yx}\) rank correlation, which is the probability of concordance minus the probability of discordance. \(D_{yx}\) can be also be written as \(D_{yx} = 2 \times (c - \frac{1}{2})\). Note that the R Hmisc package function rcorr.cens used below computes \(D_{xy}\), but \(D_{yx}(X, Y)\) is the same as \(D_{xy}(Y, X)\). \(D_{yx}\) means “discard ties on \(X\), let ties on \(Y\) count against us.” In a two-group comparison we are discarding ties on \(X\), i.e., are not comparing observations from group 1 with other observations in group 1.
Discrete Ordinal Y Example
Let’s go through the calculations and check the Wilcoxon PO OR-based approximation using data in which there is a severe violation of the PO assumption. We have three levels of \(Y\) (0, 1, 2), with the group 2 : group 1 OR for \(Y=2\) being 2.5 but the OR for \(Y \geq 1\) being 0.795. The compromise OR from assuming PO is 1.114.
C Index Dxy S.D. n missing
5.138889e-01 2.777778e-02 5.470021e-02 3.600000e+02 0.000000e+00
uncensored Relevant Pairs Concordant Uncertain
3.600000e+02 6.480000e+04 3.330000e+04 0.000000e+00
Code
conc <- b['C Index']conc
C Index
0.5138889
Now compare the concordance probability with the approximation from the PO-estimated OR:
Code
po <- ors['y']capprox <- po ^0.66/ (1+ po ^0.66)capprox
y
0.517743
The approximation is off by 0.004.
Check against the original regression equation fitted here:
Code
plogis((log(po) -0.0003) /1.5179)
y
0.5176616
Continuous Y Example
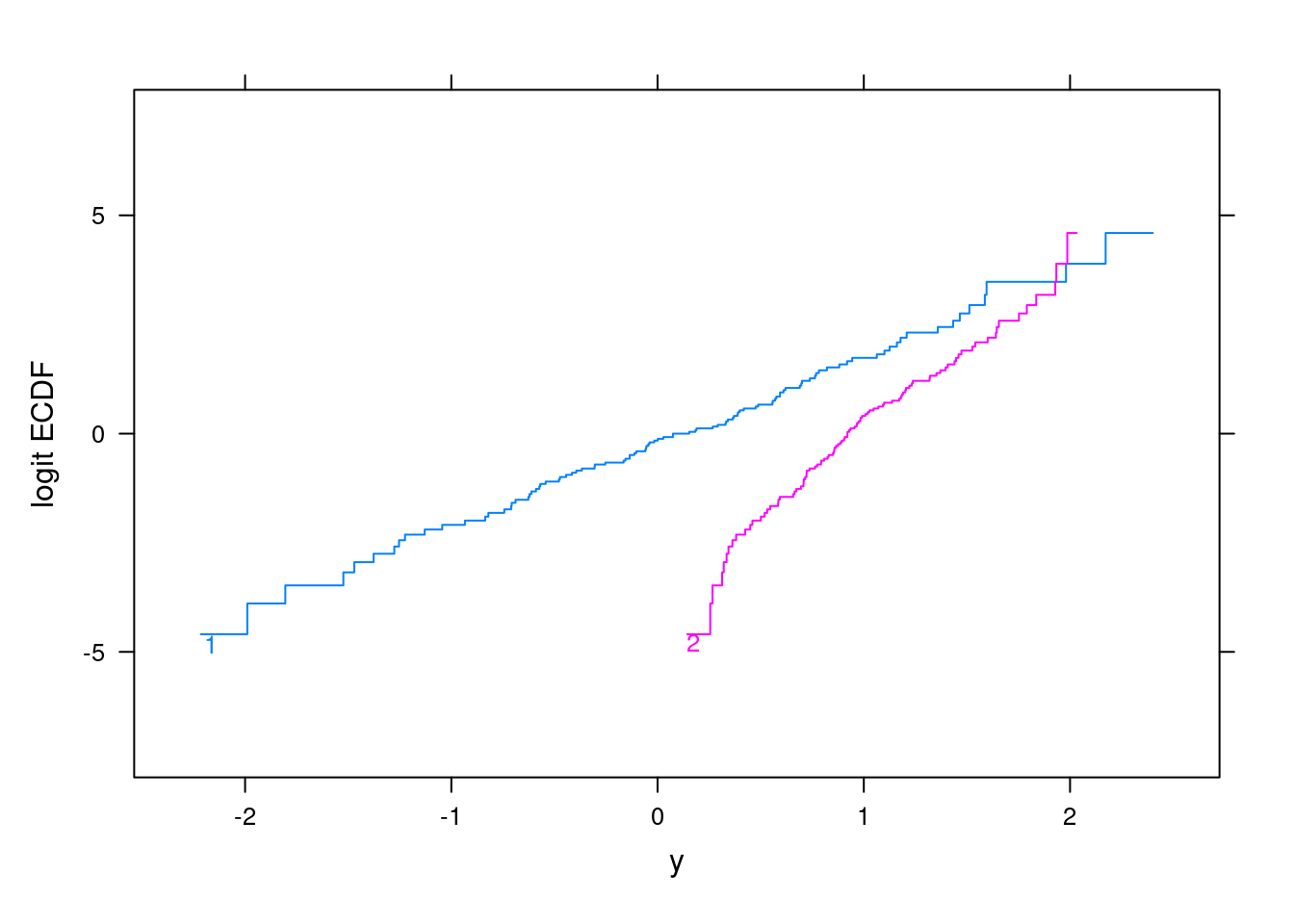
Now consider a two-sample problem with continuous Y. We could induce mild non-PO by sampling from two normal distributions with equal variance and a nonzero difference in means2. But let’s induce major non-PO by also allowing the variance in the two groups to be unequal. Draw a random sample of size 100 from a normal distribution with mean 0 and variance 1 and a second sample from a normal distribution with mean 1 and variance 0.2.
2 Note that PO would hold if one simulated from a logistic distribution with a shift in location only.
Serious non-parallelism of the logit of the two empirical cumulative distributions means serious non-proportional odds. Let’s get the \(c\) index (concordance probability) and its approximation from the PO model, as before. We use the rms package orm function which is designed to efficiently analyze continuous Y. Here the model has 199 intercepts since there are no ties in the data. Below I have back-solved for the Wilcoxon test \(\chi^2\) statistic.
R version 4.2.1 (2022-06-23)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Pop!_OS 22.04 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] rms_6.4-0 SparseM_1.81 Hmisc_4.7-2 ggplot2_3.3.5
[5] Formula_1.2-4 survival_3.4-0 lattice_0.20-45
To cite R in publications use:
R Core Team (2022).
R: A Language and Environment for Statistical Computing.
R Foundation for Statistical Computing, Vienna, Austria.
https://www.R-project.org/.
---title: If You Like the Wilcoxon Test You Must Like the Proportional Odds Modelauthor: - name: Frank Harrell url: https://hbiostat.org affiliation: Vanderbilt University<br>School of Medicine<br>Department of Biostatisticsdate: 2021-03-10categories: [ordinal, hypothesis-testing, 2021, accuracy-score, RCT, regression, metrics]description: "Since the Wilcoxon test is a special case of the proportional odds (PO) model, if one likes the Wilcoxon test, one must like the PO model. This is made more convincing by showing examples of how one may accurately compute the Wilcoxon statistic from the PO model's odds ratio."---```{r setup, include=FALSE}require(rms)knitrSet(lang='blogdown')options(prType='html')```::: {.quoteit}Clearly, the dependence of the proportional odds model on the assumption of proportionality can be over-stressed. Suppose that two different statisticians would cut the same three-point scale at different cut points. It is hard to see how anybody who could accept either dichotomy could object to the compromise answer produced by the proportional odds model. — [Stephen Senn](https://onlinelibrary.wiley.com/doi/abs/10.1002/sim.3603):::# Background The Wilcoxon-Mann-Whitney two-sample rank-sum test is a special case of the proportional odds (PO) ordinal logistic regression model. The numerator of the PO model score $\chi^2$ test for comparing two groups without covariate adjustment is exactly the Wilcoxon statistic. The equivalence of the PO model and the Wilcoxon test in this simple two-group setting is perhaps demonstrated more compellingly by showing how the Wilcoxon test statistic may be accurately approximated by a simple function of the odds ratio (OR) estimate from the PO model, even when PO is strongly violated. [[Comments](https://hbiostat.org/comment.html)]{.aside}In [Violation of Proportional Odds is Not Fatal](https://www.fharrell.com/post/po) I used simulation to derive an accurate approximation to the Wilcoxon statistic from the PO model group 2 : group 1 odds ratio estimate (OR). When the Wilcoxon statistic is re-scaled to have a 0-1 range, i.e., to a *concordance probability* $c$, the approximation is $$c = \frac{\mathrm{OR}^{0.66}}{1 + \mathrm{OR}^{0.66}}$$Over a wide variety of simulated datasets, this approximation has a mean absolute error of 0.002^[Note that $0.66 = \frac{1}{1.52}$ from the blog article.].For $n$ overall observations, $n_1$ in group 1 and $n_2$ in group 2, let $R$ denote the vector of ranks of all the observations ignoring group membership. In case of ties, midranks are used.The Wilcoxon rank-sum statistic $W$ is based on the sum of ranks in group 2. Let $X_{i}$ be [group = 2], the 1/0 indicator of being in group 2 for the $i^{\mathrm{th}}$ observation.$$W = \sum_{i=1}^{n} X_{i} R_{i} - \frac{n_{2} (n_{2} + 1)}{2}$$Letting $\bar{R}$ denote the mean of the group 2 ranks ($\frac{1}{n_{2}} \sum_{i=1}^{n} X_{i}R_{i})$, the Wilcoxon statistic is proportional to$$c = \frac{\bar{R} - \frac{n_{2} + 1}{2}}{n_{1}}$$where $c$ is the c-index or concordance probability. It is the proportion of all possible pairs of observations, one from group 2 and one from group 1, such that the the observation from group 2 is the larger of the two. Since midranks are used for ties, $c$ counts a tied pair as $\frac{1}{2}$ concordant. So letting $Y_{1}$ and $Y_{2}$ represent, respectively, random observations from groups 1 and 2, $c$ estimates $\Pr(Y_{2} > Y_{1}) + \frac{1}{2} \Pr(Y_{2} = Y_{1})$. There is an identity with Somers' $D_{yx}$ rank correlation, which is the probability of concordance minus the probability of discordance. $D_{yx}$ can be also be written as $D_{yx} = 2 \times (c - \frac{1}{2})$. Note that the R `Hmisc` package function `rcorr.cens` used below computes $D_{xy}$, but $D_{yx}(X, Y)$ is the same as $D_{xy}(Y, X)$. $D_{yx}$ means "discard ties on $X$, let ties on $Y$ count against us." In a two-group comparison we are discarding ties on $X$, i.e., are not comparing observations from group 1 with other observations in group 1.# Discrete Ordinal Y ExampleLet's go through the calculations and check the Wilcoxon PO OR-based approximation using data in which there is a severe violation of the PO assumption. We have three levels of $Y$ (0, 1, 2), with the group 2 : group 1 OR for $Y=2$ being 2.5 but the OR for $Y \geq 1$ being 0.795. The compromise OR from assuming PO is 1.114.```{r data}w <-expand.grid(group=1:2, y=0:2)n <-c(100, 110, 50, 10, 30, 60)u <- w[rep(1:6, n),]with(u, table(group, y))or2 <-exp(coef(lrm(y ==2~ group, data=u))['group'])or1 <-exp(coef(lrm(y >=1~ group, data=u))['group'])or12 <-exp(coef(lrm(y ~ group, data=u))['group'])ors <-c(or2, or1, or12)names(ors) <-c('y=2', 'y>=1', 'y')ors```Now compute the Wilcoxon statistic```{r w}wilcox.test(y ~ group, u, correct=FALSE)sumr1 <-with(u, sum(rank(y)[group ==1]))sumr2 <-with(u, sum(rank(y)[group ==2]))n1 <-sum(u$group ==1)n2 <-sum(u$group ==2)# wilcox.test uses sum of ranks in group 1W <- sumr1 - n1 * (n1 +1) /2# equals wilcox.testW# Going forward use sum of ranks in group 2W <- sumr2 - n2 * (n2 +1) /2```Compute $c$ three different ways.```{r c}W / (n1 * n2)with(u, (mean(rank(y)[group ==2]) - (n2 +1) /2) / n1)b <-with(u, rcorr.cens(y, group))bconc <- b['C Index']conc```Now compare the concordance probability with the approximation from the PO-estimated OR:```{r approx}po <- ors['y']capprox <- po ^0.66/ (1+ po ^0.66)capprox```The approximation is off by `r round(abs(capprox - conc), 3)`.Check against the original regression equation fitted [here](https://fharrell.com/post/po):```{r approx2}plogis((log(po) -0.0003) /1.5179)```# Continuous Y ExampleNow consider a two-sample problem with continuous Y. We could induce mild non-PO by sampling from two normal distributions with equal variance and a nonzero difference in means^[Note that PO would hold if one simulated from a **logistic** distribution with a shift in location only.]. But let's induce major non-PO by also allowing the variance in the two groups to be unequal. Draw a random sample of size 100 from a normal distribution with mean 0 and variance 1 and a second sample from a normal distribution with mean 1 and variance 0.2.```{r cont}set.seed(1)n1 <- n2 <-100y1 <-rnorm(n1, 0, 1)y2 <-rnorm(n1, 1, sqrt(0.2))group <-c(rep(1, n1), rep(2, n2))y <-c(y1, y2)Ecdf(~ y, group=group, fun=qlogis, ylab='logit ECDF')```Serious non-parallelism of the logit of the two empirical cumulative distributions means serious non-proportional odds. Let's get the $c$ index (concordance probability) and its approximation from the PO model, as before. We use the `rms` package `orm` function which is designed to efficiently analyze continuous Y. Here the model has 199 intercepts since there are no ties in the data. Below I have back-solved for the Wilcoxon test $\chi^2$ statistic.```{r contc,results='asis'}conc <- (mean(rank(y)[group ==2]) - (n2 +1) /2) / n1w <-wilcox.test(y ~ group)wchisq <-qchisq(1- w$p.value, 1)wchisqf <-orm(y ~ group)f``````{r contc2}or <-exp(coef(f)['group'])capprox <- or ^0.66/ (1+ or ^0.66)z <-c(conc, capprox, or)names(z) <-c('c-index', 'c-approx', 'OR')z```The approximation is off by `r round(abs(conc - capprox), 3)`.# Further Reading* <https://hbiostat.org/bib/po>* <https://hbiostat.org/blog/#category=ordinal>* <https://fharrell.com/post/rpo># Computing Environment`r markupSpecs$html$session()`