In randomized clinical trials, power can be greatly increased and sample size reduced by using an ordinal outcome instead of a binary one. The proportional odds model is the most popular model for analyzing ordinal outcomes, and it borrows treatment effect information across outcome levels to obtain a single overall treatment effect as an odds ratio. When deaths can occur, it is logical to have death as one of the ordinal categories. Consumers of the results frequently seek evidence of a mortality reduction even though they were not willing to fund a study large enough to be able to detect this with decent power. The same goes when assessing whether there is an increase in mortality, indicating a severe safety problem for the new treatment. The partial proportional odds model provides a continuous bridge between standalone evidence for a mortality effect and obtaining evidence using statistically richer information on the combination of nonfatal and fatal endpoints. A simulation demonstrates the relationship between the amount of borrowing of treatment effect across outcome levels and the Bayesian power for finding evidence for a mortality reduction.
Department of Biostatistics Vanderbilt University School of Medicine
Published
April 30, 2024
Modified
April 24, 2025
Background
As explained here, the power for a group comparison can be greatly increased over that provided by a binary endpoint, with greater increase when an ordinal endpoint has several well-populated categories or has a great many categories, in which it becomes a standard continuous variable. When a randomized clinical trial (RCT) is undertaken and deaths can occur, there are disadvantages to
excluding the death and analyzing responses only on survivors
using death as a competing risk, which makes for hard-to-interpret results and doesn’t penalize efficacy for death
using a complex estimand that involves counterfactuals or other complexities
By making death the worst level of an ordinal response \(Y\), nothing is swept under the rug, and a treatment having more deaths is penalized for that. Evidence for treatment effectiveness may be driven by the nonfatal outcomes. Suppose for example that \(Y\) is renal function at 6 weeks, measured by serum creatinine, with death coded as a value higher than the highest observed creatinine (it doesn’t matter how high for ordinal analyses). Evidence for treatment effectiveness in improving \(Y\) may be stated as “the treatment improved renal function accounting for death”.
Often sponsors want evidence for a specific effect on mortality, even though they are unwilling to budget for a study large enough to provide evidence for a mortality benefit on its own. In that case, the only way to have Bayesian or frequentist power to detect a mortality improvement is to assume that some of the treatment benefit on nonfatal outcome components spills over to mortality. The partial proportional odds (PO) semiparametric ordinal logistic regression model by Peterson & Harrell, 1990 when coupled with a Bayesian implementation of the model provides a very formal way to borrow treatment effect information across levels of Y.
Suppose that for simplicity we ignore power-enhancing baseline covariates, and have an outcome variable \(Y=0, 1, \ldots, k\) where \(Y=k\) represents death. The PO model can be written as
where \(y > 0\), \(\mathrm{expit}(x) = \frac{1}{1 + \exp(-x)}\) (inverse logit), \(\alpha_y\) is the intercept corresponding to a \(Y\) cutoff of \(y\) (\(y = 1, \ldots, k\)), \(X=1\) for treatment B and \(X=0\) for treatment A, and \(\beta\) is the B:A log odds ratio. Hence \(\exp(\beta)\) is the B:A odds ratio (OR). Under the PO assumption the \(k\) possible B:A ORs for \(Y \geq y\) are the same for all \(y\). For example the treatment effect on death is \(\exp(\beta)\), just like the treatment effect on the last three \(Y\) categories combined, for example \(Y \geq 3\) if \(k=5\).
Peterson and Harrell proposed the partial PO model and the constrained partial PO model. Using the latter we allow for a special effect of treatment only on Y=\(k\) and assume a constant OR for all other \(Y\)-cutoffs, for example. This constrained partial PO model is
where \([Y=k]\) is an indicator variable that is \(1\) if \(Y=k\), \(0\) otherwise. \(\tau\) represents a “special effect of treatment B” for \(Y=k\). So the B:A odds ratio for \(Y=k\) is \(\exp(\beta + \tau)\).
If the model is fitted using a frequentist maximum likelihood approach, or using a Bayesian procedure that puts a non-informative prior on \(\tau\), the precision of \(\beta + \tau\) (or its anti-log, the OR for mortality) will come from the effective sample size for a pure death outcome.
Example Partial Proportional Odds Analysis
Suppose that we have a parallel-group two-treatment randomized trial, and are in the bizarre situation where there are no patient risk factors, i.e., patient outcomes are homogeneous within treatment so that no covariates are needed. The treatment is designed to keep hospitalized patients from requiring mechanical ventilation, and hopefully also to lower in-hospital mortality. Suppose the outcomes are \(Y=0, 1, 2\) for alive and not on ventilator, alive and on ventilator, or dead, respectively. Suppose the following outcome frequencies and summary statistics arise.
Code
require(Hmisc)require(rmsb)require(data.table)require(ggplot2)options(prType='html',datatable.print.topn=50, datatable.print.class=FALSE,mc.cores=4, rmsb.backend='cmdstan')cmdstanr::set_cmdstan_path(cmdstan.loc) # cmdstan.loc is in ~/.Rprofilek <-rbind(A =c(300, 70, 30),B =c(335, 40, 25))colnames(k) <-c('0', '1', '2')p <- k /400cs <-function(x) rev(cumsum(rev(x)))cp <-rbind(A=cs(p[1,]), B=cs(p[2,]))or <-function(p) { ob <- p[2] / (1- p[2]) oa <- p[1] / (1- p[1]) ob / oa}OR <-c(or(cp[, 2]), or(cp[, 3]))names(OR) <-c('Y>=1', 'Y=2')rOR <- OR[2] / OR[1]printL(Frequencies=k, Proportions=p, 'Cumulative Proportions'=cp, # printL in Hmisc'B:A Odds Ratios'=OR, 'Y=2 : Y>=1 Ratio of Odds Ratios'=rOR, dec=4)
Frequencies:
0 1 2
A 300 70 30
B 335 40 25
Proportions:
0 1 2
A 0.7500 0.175 0.0750
B 0.8375 0.100 0.0625
Cumulative Proportions:
0 1 2
A 1 0.2500 0.0750
B 1 0.1625 0.0625
B:A Odds Ratios:
Y>=1 Y=2
0.5821 0.8222
Y=2 : Y>=1 Ratio of Odds Ratios: 1.4125
Create a one row per patient dataset and fit a Bayesian constrained partial PO model using the rmsb package blrm function. Start by using noninformative priors for the overall B:A treatment effect \(\beta\) and the extra treatment effect on death, \(\tau\).
Code
# Create one row per patientw <-expand.grid(tx=c('A', 'B'), y=0:2)setDT(w)d <- w[, .(y=rep(y, k[tx, as.character(y)])), by=.(tx, y)]# Define the form of non-PO: special effect for deathg <-function(y) 1* (y ==2)# Second formula given to blrm specifies predictors allowed# to operate in non-POset.seed(11)f <-blrm(y ~ tx, ~ tx, cppo=g, data=d)
Running MCMC with 4 parallel chains...
Chain 1 finished in 1.7 seconds.
Chain 2 finished in 1.6 seconds.
Chain 4 finished in 1.6 seconds.
Chain 3 finished in 1.7 seconds.
All 4 chains finished successfully.
Mean chain execution time: 1.7 seconds.
Total execution time: 1.9 seconds.
Code
f
Bayesian Constrained Partial Proportional Odds Ordinal Logistic Model
Dirichlet Priors With Concentration Parameter 0.541 for Intercepts
blrm(formula = y ~ tx, ppo = ~tx, cppo = g, data = d)
Mixed Calibration/
Discrimination Indexes
Discrimination
Indexes
Rank Discrim.
Indexes
Obs 800
LOO log L -510.89±23.29
g 0.269 [0.088, 0.44]
C 0.62 [0.62, 0.62]
0 635
LOO IC 1021.78±46.57
gp 0.043 [0.015, 0.069]
Dxy 0.239 [0.24, 0.24]
1 110
Effective p 4.04±0.28
EV 0.013 [0.001, 0.028]
2 55
B 0.162 [0.162, 0.163]
v 0.081 [0, 0.175]
Draws 4000
vp 0.002 [0, 0.005]
Chains 4
Time 2.7s
p 1
Mode β
Mean β
Median β
S.E.
Lower
Upper
Pr(β>0)
Symmetry
y≥1
-1.0986
-1.0942
-1.0933
0.1156
-1.3127
-0.8668
0.0000
0.99
y≥2
-2.5123
-2.5236
-2.5188
0.1867
-2.9084
-2.1747
0.0000
0.94
tx=B
-0.5412
-0.5461
-0.5458
0.1837
-0.8951
-0.1671
0.0008
0.98
tx=B x f(y)
0.3454
0.3406
0.3418
0.2379
-0.1342
0.7939
0.9188
0.99
From the output there is a very low probability that \(\beta > 0\), i.e., a very high probability that \(\beta < 0\), i.e., that treatment B is beneficial.
Compute posterior mode odds ratios from this fit and compare to the observed ORs.
Code
h <-function(f) { k <-coef(f, stat='mode') beta <- k['tx=B'] tau <- k['tx=B x f(y)'] or <-c(exp(beta), exp(beta + tau), exp(tau))names(or) =c('B:A overall', 'B:A Y=2', 'Y=2:Y>=1')printL('Posterior mode odds ratios'=or)}h(f)
The Bayesian estimates are virtually the same as the empirical estimates.
Now add informative priors. For the overall treatment effect \(\beta\) the prior is chosen so that there is only a 0.025 chance of the OR exceeding 4 and a 0.025 chance of being below \(\frac{1}{4}\). For the departure from PO, \(\tau\) represents the log of the ratio of the OR for death to the OR for the general effect of treatment denoted by \(\log(r)\). The prior of \(\tau\) is chosen so that there is a 0.9 chance that \(r\) is in the interval \([\frac{1}{2}, 2]\). So we are assuming it is unlikely that the treatment effect on death differs from the general effect by more than a factor of 2 in either direction.
For the blrm function priors are stated in terms of contrasts so that convenient user data units can be used.
The parameters are attenuated by the skeptical priors.
Compute the probability of an overall effect, a treatment effect on mortality, and the probability that the the differential treatment effect on mortality vs. overall is by more than a factor of 1.2.
Code
# The rmsb function PostF makes it easy to compute posterior probs.# of any assertions (by computing proportion of posterior draws # meeting the conditions)P <-PostF(f, pr=TRUE)
Original Name Short Name
y>=1 a1
y>=2 a2
tx=B b1
tx=B x f(y) b2
Code
printL('Pr(beta < 0)'=P(b1 <0),'Pr(beta + tau < 0)'=P(b1 + b2 <0),'Pr(ratio of ORS > fold change of 1.2)'=P(abs(b2) >log(1.2)), dec=4)
Pr(beta < 0): 0.9985
Pr(beta + tau < 0): 0.8318
Pr(ratio of ORS > fold change of 1.2): 0.6587
We see strong evidence for an overall treatment benefit, moderate evidence for a mortality reduction, and little evidence for a strong non-PO effect, i.e., ratio of ORs \(> 1.2\) or \(< \frac{1}{1.2}\). In other words, there is not much evidence for an inconsistent treatment effect. To be fair, there is not much evidence for a consistent treatment effect either, using a cutoff for \(r\) of 1.2 or its reciprocal.
Six-level Outcome Example and Frequentist Power
Suppose that in the control group we expect the following proportions of levels of \(Y\).
Code
p <-c(.2, .32, .2, .105, .1, 0.075)names(p) <-paste0('Y=', 0:5)p
So the probability of death in treatment A is 0.075. Say we want to detect a common OR of 0.65 with 0.9 power at \(\alpha=0.05\) with equal sample sizes in the two groups. The needed sample size for the full ordinal outcome is computed below using the R Hmisc package posamsize function. For us to have any hope of detecting a mortality difference, set the binary outcome power to 0.5.
This function needs the average probabilities over the two treatments so we have move the probabilities by the square root of the odds ratio to get the averages and still set up for the target OR in the B:A comparison. The pomodm function in Hmisc does the needed OR shifting of probabilities.
Code
or <-0.65pmid <-pomodm(p=p, odds.ratio=sqrt(or))pB <-pomodm(p=p, odds.ratio=or)round(rbind(A=p, B=pB, Average=pmid), 3)
Y=0 Y=1 Y=2 Y=3 Y=4 Y=5
A 0.200 0.320 0.200 0.105 0.100 0.075
B 0.278 0.347 0.173 0.081 0.071 0.050
Average 0.237 0.337 0.188 0.093 0.085 0.061
Code
nord <-round(posamsize(p=pmid, odds.ratio=or, power=0.9)$n)printL('Sample size needed for ordinal Y'= nord)
Sample size needed for ordinal Y: 723
Code
pdeath1 <- p[length(p)]pdeath2 <-plogis(qlogis(pdeath1) +log(or))printL('Probabilities of death for the two treatments'=c(pdeath1, pdeath2), dec=4)
Probabilities of death for the two treatments:
Y=5 Y=5
0.0750 0.0501
Code
nbin <-round(sum(bsamsize(pdeath1, pdeath2, power=0.5)))printL('Sample size needed for binary Y'= nbin)
Sample size needed for binary Y: 1449
Code
n <-max(nord, nbin)# Check OR for mortalityprintL('OR for mortality:'= (0.05/0.95)/(0.075/0.925), dec=3)
OR for mortality:: 0.649
Select as the study sample size the minimum of the sample sizes needed for the ordinal comparison (at 0.9 power) and for the binary comparison (at 0.5 power). The total sample size needed is \(n\)=1449.
As a check, compute the power for the standalone mortality comparison using the PO/Wilcoxon test formula.
Code
printL('Binomial test power'=bpower(0.075, odds.ratio=or, n=n), dec=3)
Binomial test power: 0.5
Code
pmA <-c(1- p[6], p[6])pmMid <-c(1- pmid[6], pmid[6])printL('Ordinal test power for binary Y'=popower(p=pmMid, odds.ratio=or, n=n))
Ordinal test power for binary Y:
Power: 0.503
Efficiency of design compared with continuous response: 0.173
Approximate standard error of log odds ratio: 0.2191
More About Bayesian Borrowing
The assumption we’ll make is that there is some similarity of treatment effect on \(Y=1, \ldots, 4\) as there is on \(Y=5\) (death). Similarity will be expressed as how likely it is for the effect on \(Y=5\) to be very different than the effect on \(Y=1, \ldots, 4\). The similarity of treatment effects is captured by the ratio of two odds ratios—the B:A OR for \(Y=5\) and the B:A OR for \(Y\geq y\) where \(0 < y < 5\) : \(\frac{\exp(\beta + \tau)}{\exp(\beta)} = \exp(\tau)\). Let’s put a prior on \(\tau\), the log ratio of ORs, such that it is equally likely that the ratio falls is below 1 as it is above 1. Use a Gaussian (normal) prior distribution for the log ratio, \(\tau\), with mean zero to accomplish this. Then select the standard deviation of the normal distribution to control the amount of borrowing of treatment effect information across \(Y\) levels.
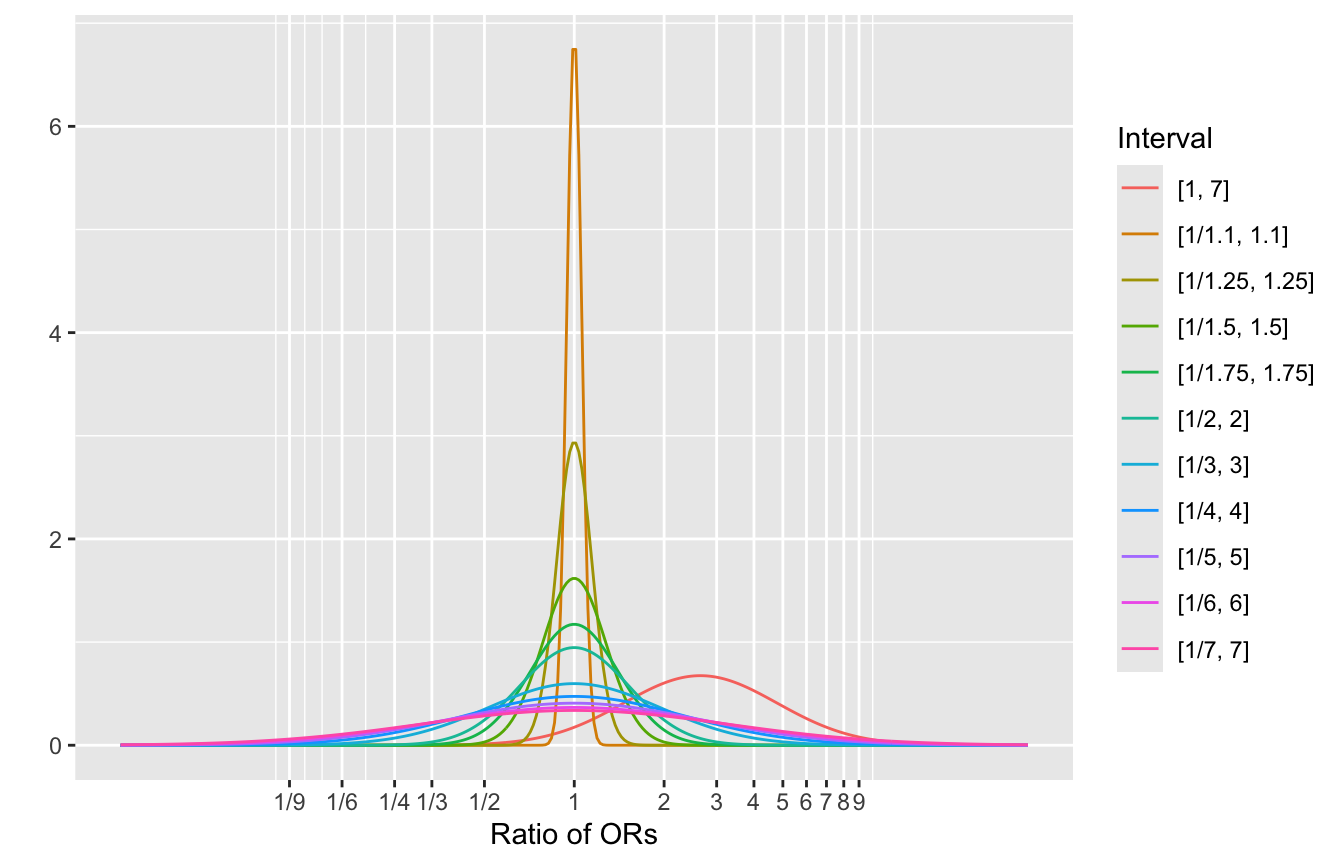
Let \(r\) be the ratio of ORs as before. Skepticism against \(r\) being far from 1.0 (closeness to 1.0 indicating a belief that the mortality effect is similar to the other effects) can be specified in many ways. One way is by selecting an interval \([a, b]\) for which one believes there is a chance of 0.9 of \(r\) being in that interval. Let’s make the tail areas equal so that \(\Pr(r < a) = \Pr(r > b) = 0.05\). If \(a = \frac{1}{b}\) then \(\log(a) = -\log(b)\) and if \(\log(r)\) has a normal distribution with mean \(\mu\) and standard deviation \(\sigma\) then \(\mu=0\) in this symmetric case. In general \(\mu = \frac{\log(b) + \log(a)}{2}\) and \(\sigma=\frac{\log(b) - \log(a)}{2q}\) where \(q = \Phi^{-1}(0.95) = 1.645\), the 0.95 quantile of the standard normal distribution.
For a variety of \(a, b\) here are the corresponding prior distribution mean and standard deviations. All but the last has \(a = \frac{1}{b}\) and so has a mean of zero. The last one, \([1, 7]\), gives only a 0.05 chance for the treatment effect on mortality to be better (smaller OR) than the effect on the other outcome levels.
Bayesian power is taken to mean the probability that the posterior probability of a benefit on mortality exceeds 0.95. For a total \(n\)=1449 use the blrm function to fit the constrained partial PO model with a variety 0.9 intervals for \(r\). The intervals are symmetric in \(\log(r)\). By simulating 1000 upper \(r\) 0.9 interval values we don’t need to replicate any one of them in the simulations as we can just interpolate/smooth over the iterations to estimate Bayesian power as a function of the 0.9 interval chosen.
The constraint for partial PO will be such that it applies to death (\(Y=5\)). The prior for the main treatment effect \(\beta\) will be left as non-informative, and the prior for the mortality-differential treatment effect \(\tau\) is specified through a non-PO contrast (argument npcontrast to blrm).
In this simulation, the data generating mechanism is such that the treatment effect is constant (OR=0.65) across all levels of outcomes. The analysis of a mortality-specific effect does not have access to this information.
Code
w <-data.table(b =seq(1.01, 4, length=1000)) # using intervals [1/b, b]w[, sigma :=log(b) /1.644854]# Function to simulate one sample and compute the posterior probability# of treatment benefit on mortalitysim1 <-function(n, pcontrol, or=0.65, sigma) {# n: number of pts in each group# pcontrol: vector of outcome probabilities for control group# or: odds ratio to detect i <<- i +1cat(i, '\n', file='/tmp/z')# Compute outcome probabilities for new treatment ptr <-pomodm(p=pcontrol, odds.ratio=or) k <-length(pcontrol) -1 tx <-c(rep(0, n), rep(1, n)) y <-c(sample(0: k, n, replace=TRUE, prob=pcontrol),sample(0: k, n, replace=TRUE, prob=ptr) )# Set prior on the "treatment by Y interaction" contrast npcon <-list(sd=sigma, c1=list(tx=1), c2=list(tx=0),contrast=expression(c1 - c2)) f <-blrm(y ~ tx, y ~ tx, cppo=function(y) y ==5,npcontrast=npcon,loo=FALSE, method='sampling', iter=1000) beta <- f$draws[, 'tx'] tau <- f$draws[, 'tx x f(y)']list(p1=mean(beta <0), p2=mean(beta + tau <0), p3=mean(abs(tau) >0.2))}g <-function() {set.seed(7) R <-copy(w) R[, sim1(round(n /2), p, sigma=sigma), by=.(sigma, b)]}i <-0R <-runifChanged(g, w, n, file='sim.rds')
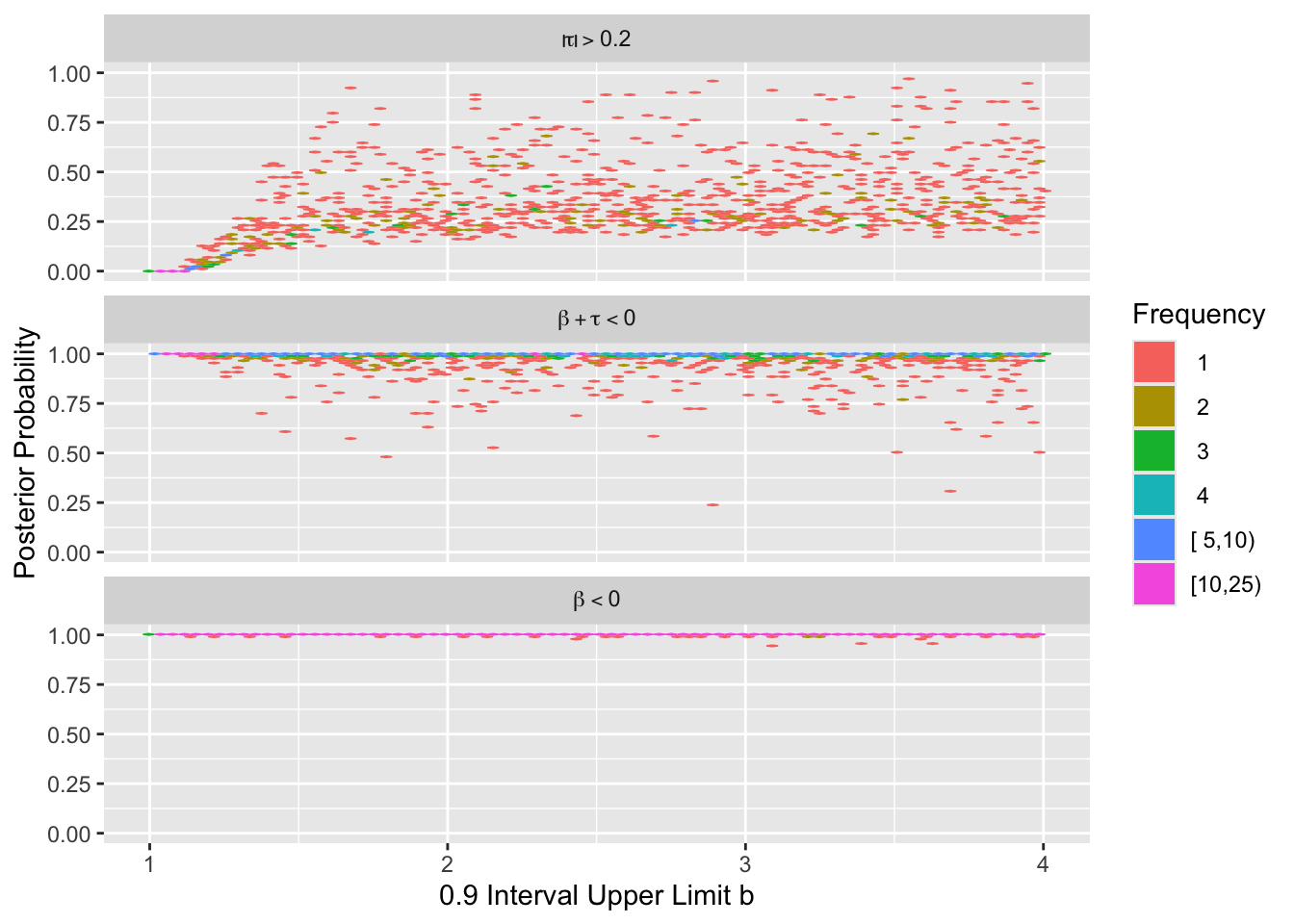
Look at the distribution of the three posterior probabilities.
# Find b such that power is 0.8b8 <- m[variable=='beta + tau < 0'& Type=='LR',approx(hit, b, xout=0.8)$y]b8 <-round(c(1/ b8, b8), 3)printL('0.9 Interval for r yielding 0.8 power for mortality assessment'= b8)
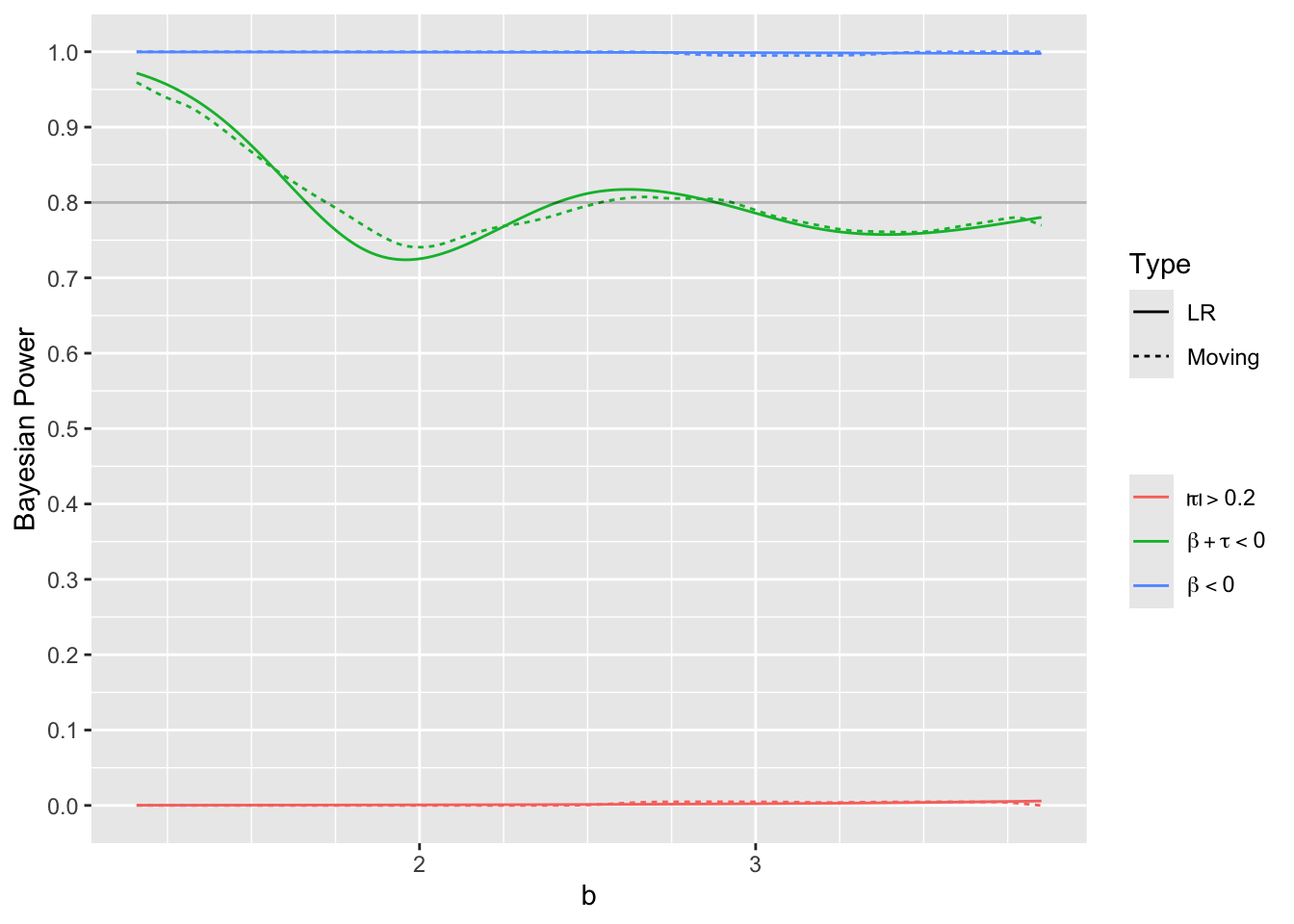
0.9 Interval for r yielding 0.8 power for mortality assessment: 0.416, 2.403
The posterior probability that \(|\tau| > 0.2\) hovered around zero, which is good since data were generated assuming PO. Bayesian power for the overall treatment effect is nearly 1.0. The minimum value of \(b\) required to achieve 0.8 Bayesian power is 2.403.
What Constraints Does a Partial PO Model Place on \(Y\)-specific Treatment Effects?
Consider a 4-level dependent variable \(Y=0,1,2,3\), a 2-level baseline covariate \(Z=0, 1\), and a 2-level treatment \(X=0,1\). Assume a partial proportional odds (PPO) model
\[P(Y \geq y | X, Z) = \text{expit}(\alpha_{y} + \beta X + \gamma Z + \tau_{1} X[y=2] + \tau_{2} X[y=3])\]
Make \(P(Y \geq y | X=0, Z=0) = 0.3, 0.2, 0.1\) when \(y=1, 2, 3\), allowing solving for \(\alpha\).
Let Z, for which PO is assumed, have an odds ratio (OR) of \(\frac{0.4/0.6}{0.3/0.7} = \exp(\gamma)\) so that \(P(Y \geq 1 | X=0, Z=1) = 0.4 = \text{expit}(\alpha_{1} + \gamma)\).
Code
gamma <-log((0.4/0.6) / (0.3/0.7))gamma
[1] 0.4418328
Let the \(X=1:0\) OR for \(Y\geq 1\) be 0.7 so that \(\beta = \log(0.7)\). Now the only free parameters are the non-PO parameters \(\tau_{1}, \tau_{2}\).
Code
beta <-log(0.7)beta
[1] -0.3566749
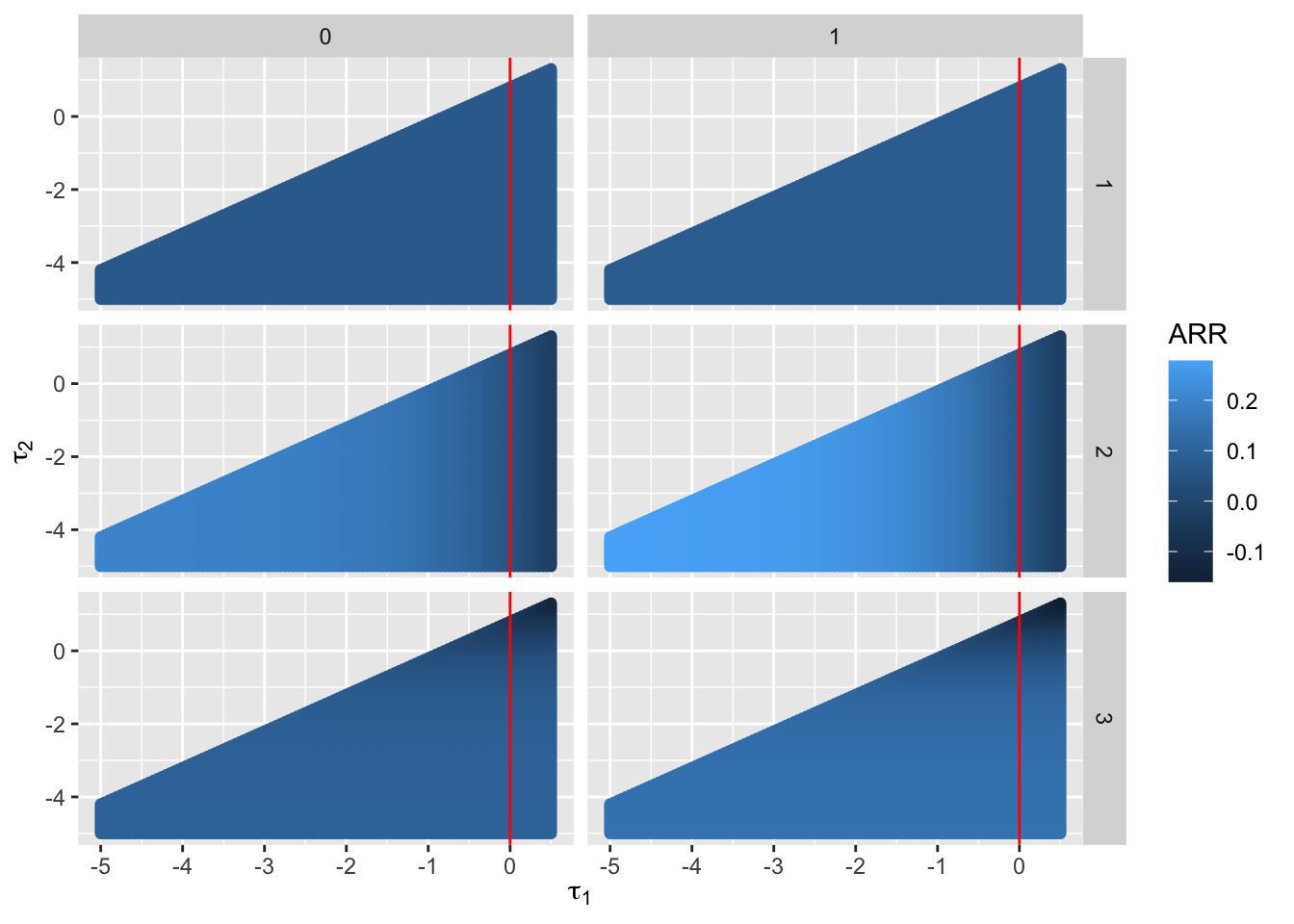
Vary \(\tau\) over a regular grid and plot the resulting differences in probabilities corresponding to \(y=1, 2, 3\), separately for each \(Z\). These differences are absolute risk reductions (ARR) due to treatment (\(X=1\)), with ARR=0 corresponding to OR=1.
It is important to note that for all the cell probabilities (differences in consecutive cumulative probabilities) to be legal, i.e., in \([0,1]\), it is necessary that the intercepts in effect be in descending order. The intercepts in effect are the within-\(y\) sums of all terms that change with \(y\). This includes the main \(\alpha\) intercepts and applicable \(\tau\)s. \(\tau\) is applicable only when \(X=1\), so consider the \(X=1\) case where the model is
when the ignorable \(Z\) is zero. The intercepts in effect when \(y=1, 2, 3\), respectively, are \(\alpha_{1}\), \(\alpha_{2} + \tau_{1}\) and \(\alpha_{3} + \tau_{2}\). So the requirement is
Little restriction is placed on the treatment effect on \(Y=3\) when a special treatment effect is also allowed for \(Y=2\) (ARR ranges over \([-0.16, 0.145]\)). Now restrict attention to the special case of not allowing a special non-PO treatment effect on \(Y=2\), i.e., when \(\tau_{1}=0\) which is along the vertical lines in the graph. As makes sense, ARR does not vary with \(\tau_{2}\) when considering ARR for \(Y\geq 1\) and for \(Y \geq 2\). For \(Y \geq 3\) (the bottow row of the graph), there remains a range of ARR from -0.065 to 0.145. A constrained partial PO model with only a special effect of \(X\) when \(y=3\) allows the treatment to be completely ineffective on death in this example, and allows for up to a 0.065 increase in mortality risk.
Note that ARR is restricted to be \(\leq 0.275\) since the base risks are \(< 0.5\). This restriction is essentially the restriction of having non-negative \(P(Y \geq y)\).
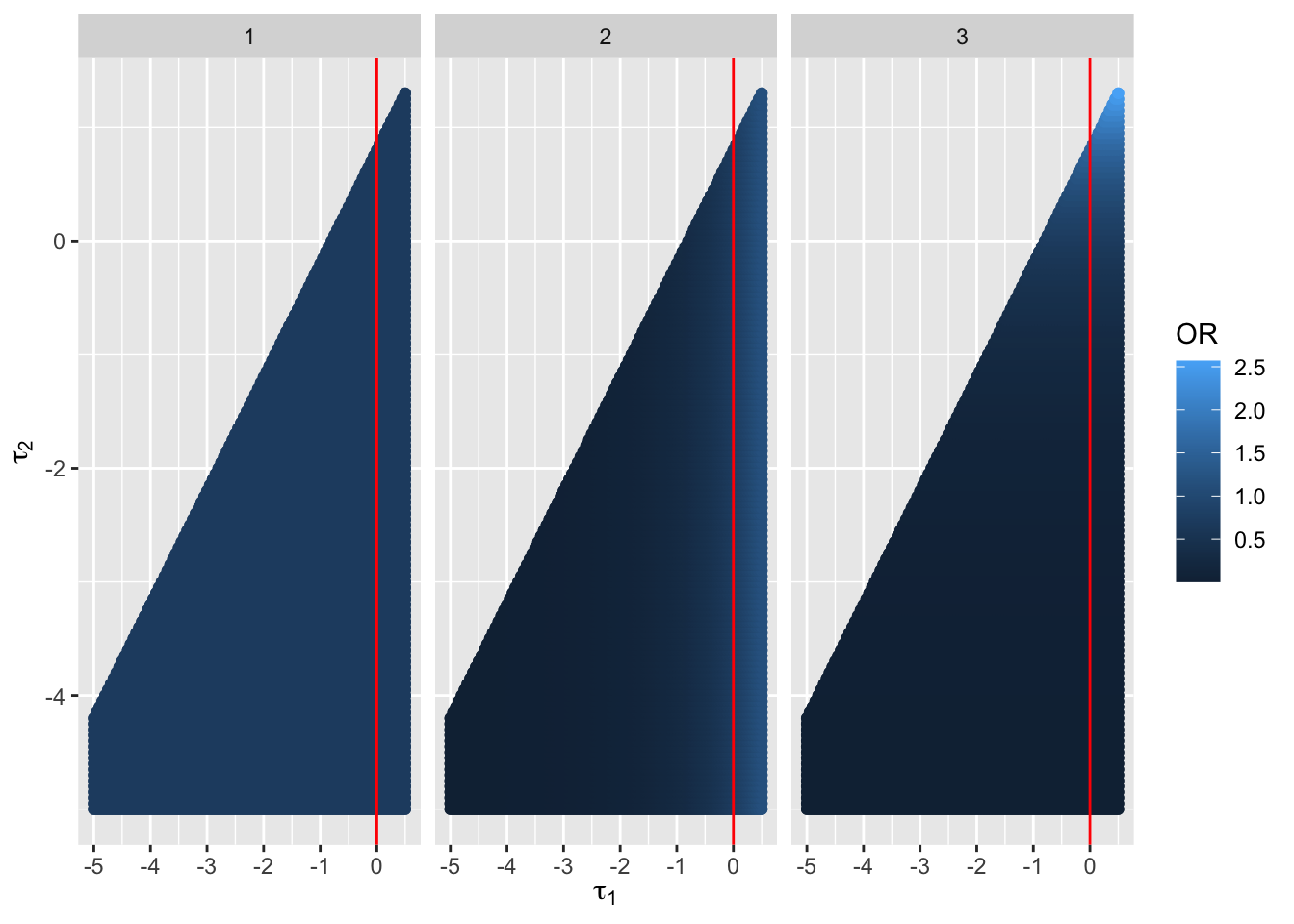
Now consider the different ORs allowed in the partial PO models.
The is virtually no limit on how small OR can be when \(\tau_{1}=0\). Concerning treatment worsening the chance of \(Y=3\), by only allowing a special treatment effect for \(y=3\) the upper limit of allowed OR is 1.56.
NoteA Note About Time To Event
Our example considers death as a binary event. Analyzing it instead as time-to-event in its own model will allow for variable follow-up time and will increase power if deaths are common. If the incidence of death is low as in our simulation design, little power is gained from utilizing event times.
A Markov longitudinal ordinal model can jointly analyze ordinal responses as well as time to event while allowing for variable follow-up.
Summary
The partial proportional odds model provides a formal way to quantify evidence for a treatment effect on a given interval of an ordinal outcome. When one of the outcomes is very important but relatively rare, it is difficult to size studies to have power to show a treatment effect on that outcome without borrowing some information from the treatment effect on the outcomes that have a higher effective sample size. The question is how much borrowing is clinically acceptable. The above simulation example shows how much borrowing is required for power for a treatment comparison on the highest outcome level to be adequate. Researchers can run similar simulations for their situations, and judge whether the amount of borrowing needed for adequate Bayesian power is justifiable. In the simulation, the required amount of borrowing to achieve at least 0.8 Bayesian power for mortality assessment involves assuming that the differential treatment effect on mortality (ratio of two odds ratios) is in the interval \([0.416,2.403]\) with 0.9 probability, or is in a narrower interval.
A separate simulation was done using \(\frac{1}{2}\) the sample size. The amount of borrowing needed to achieve 0.8 Bayesian power for a mortality assessment was \(b=1.3\). A good rule of thumb may be to expect to need a power of a standalone mortality assessment to be at least 0.5 for the Bayesian power to be sufficient with a reasonable amount of borrowing.
When a study doesn’t have a good chance of demonstrating a mortality difference with little or no borrowing of information across levels of \(Y\), it may be important to clinically pre-specify the prior for the inconsistency of mortality and non-fatal effects before the study, and to stick with that for computing the posterior probability of a mortality benefit.
It is important to note that because the PO model is always consistent with a Wilcoxon test in terms of the direction of a treatment effect (and whether the effect is zero), the more powerful PO model that does not include the partial PO parameter for a special effect of treatment on mortality will have strong ability to discern which treatment is better overall, penalizing for death, if there is clinical consensus on the outcome rankings. This is despite the problem caused by strong violation of PO for the treatment variable: the PO model may give the wrong assessment of the isolated effect of treatment on mortality.
---title: "Borrowing Information Across Outcomes"author: - name: Frank Harrell url: https://hbiostat.org affiliation: Department of Biostatistics<br>Vanderbilt University School of Medicinedate: 2024-04-30date-modified: last-modifiedcategories: [bayes, design, RCT, accuracy-score, inference, ordinal, 2024]description: "In randomized clinical trials, power can be greatly increased and sample size reduced by using an ordinal outcome instead of a binary one. The proportional odds model is the most popular model for analyzing ordinal outcomes, and it borrows treatment effect information across outcome levels to obtain a single overall treatment effect as an odds ratio. When deaths can occur, it is logical to have death as one of the ordinal categories. Consumers of the results frequently seek evidence of a mortality reduction even though they were not willing to fund a study large enough to be able to detect this with decent power. The same goes when assessing whether there is an increase in mortality, indicating a severe safety problem for the new treatment. The partial proportional odds model provides a continuous bridge between standalone evidence for a mortality effect and obtaining evidence using statistically richer information on the combination of nonfatal and fatal endpoints. A simulation demonstrates the relationship between the amount of borrowing of treatment effect across outcome levels and the Bayesian power for finding evidence for a mortality reduction."---## BackgroundAs explained [here](/post/ordinal-info), the power for a group comparison can be greatly increased over that provided by a binary endpoint, with greater increase when an ordinal endpoint has several well-populated categories or has a great many categories, in which it becomes a standard continuous variable. When a randomized clinical trial (RCT) is undertaken and deaths can occur, there are disadvantages to* excluding the death and analyzing responses only on survivors* using death as a competing risk, which makes for hard-to-interpret results and doesn't penalize efficacy for death* using a complex estimand that involves counterfactuals or other complexitiesBy making death the worst level of an ordinal response $Y$, nothing is swept under the rug, and a treatment having more deaths is penalized for that. Evidence for treatment effectiveness may be driven by the nonfatal outcomes. Suppose for example that $Y$ is renal function at 6 weeks, measured by serum creatinine, with death coded as a value higher than the highest observed creatinine (it doesn't matter how high for ordinal analyses). Evidence for treatment effectiveness in improving $Y$ may be stated as "the treatment improved renal function accounting for death".Often sponsors want evidence for a specific effect on mortality, even though they are unwilling to budget for a study large enough to provide evidence for a mortality benefit on its own. In that case, the only way to have Bayesian or frequentist power to detect a mortality improvement is to assume that some of the treatment benefit on nonfatal outcome components spills over to mortality. The partial proportional odds (PO) semiparametric ordinal logistic regression model by [Peterson & Harrell, 1990](https://www.jstor.org/stable/2347760) when coupled with a [Bayesian implementation of the model](https://hbiostat.org/r/rmsb) provides a very formal way to borrow treatment effect information across levels of Y.Suppose that for simplicity we ignore power-enhancing baseline covariates, and have an outcome variable $Y=0, 1, \ldots, k$ where $Y=k$ represents death. The PO model can be written as$$\Pr(Y \geq y) = \mathrm{expit}(\alpha_{y} + X\beta)$$where $y > 0$, $\mathrm{expit}(x) = \frac{1}{1 + \exp(-x)}$ (inverse logit), $\alpha_y$ is the intercept corresponding to a $Y$ cutoff of $y$ ($y = 1, \ldots, k$), $X=1$ for treatment B and $X=0$ for treatment A, and $\beta$ is the B:A log odds ratio. Hence $\exp(\beta)$ is the B:A odds ratio (OR). Under the PO assumption the $k$ possible B:A ORs for $Y \geq y$ are the same for all $y$. For example the treatment effect on death is $\exp(\beta)$, just like the treatment effect on the last three $Y$ categories combined, for example $Y \geq 3$ if $k=5$.Peterson and Harrell proposed the _partial PO model_ and the _constrained partial PO model_. Using the latter we allow for a special effect of treatment only on Y=$k$ and assume a constant OR for all other $Y$-cutoffs, for example. This constrained partial PO model is$$\Pr(Y \geq y) = \mathrm{expit}(\alpha_{y} + X\beta + X[Y=k]\tau)$$where $[Y=k]$ is an indicator variable that is $1$ if $Y=k$, $0$ otherwise. $\tau$ represents a "special effect of treatment B" for $Y=k$. So the B:A odds ratio for $Y=k$ is $\exp(\beta + \tau)$.If the model is fitted using a frequentist maximum likelihood approach, or using a Bayesian procedure that puts a non-informative prior on $\tau$, the precision of $\beta + \tau$ (or its anti-log, the OR for mortality) will come from the effective sample size for a pure death outcome.## Example Partial Proportional Odds AnalysisSuppose that we have a parallel-group two-treatment randomized trial, and are in the bizarre situation where there are no patient risk factors, i.e., patient outcomes are homogeneous within treatment so that no covariates are needed. The treatment is designed to keep hospitalized patients from requiring mechanical ventilation, and hopefully also to lower in-hospital mortality. Suppose the outcomes are $Y=0, 1, 2$ for alive and not on ventilator, alive and on ventilator, or dead, respectively. Suppose the following outcome frequencies and summary statistics arise.```{r}require(Hmisc)require(rmsb)require(data.table)require(ggplot2)options(prType='html',datatable.print.topn=50, datatable.print.class=FALSE,mc.cores=4, rmsb.backend='cmdstan')cmdstanr::set_cmdstan_path(cmdstan.loc) # cmdstan.loc is in ~/.Rprofilek <-rbind(A =c(300, 70, 30),B =c(335, 40, 25))colnames(k) <-c('0', '1', '2')p <- k /400cs <-function(x) rev(cumsum(rev(x)))cp <-rbind(A=cs(p[1,]), B=cs(p[2,]))or <-function(p) { ob <- p[2] / (1- p[2]) oa <- p[1] / (1- p[1]) ob / oa}OR <-c(or(cp[, 2]), or(cp[, 3]))names(OR) <-c('Y>=1', 'Y=2')rOR <- OR[2] / OR[1]printL(Frequencies=k, Proportions=p, 'Cumulative Proportions'=cp, # printL in Hmisc'B:A Odds Ratios'=OR, 'Y=2 : Y>=1 Ratio of Odds Ratios'=rOR, dec=4)```Create a one row per patient dataset and fit a Bayesian constrained partial PO model using the `rmsb` package `blrm` function. Start by using noninformative priors for the overall B:A treatment effect $\beta$ and the extra treatment effect on death, $\tau$.```{r}# Create one row per patientw <-expand.grid(tx=c('A', 'B'), y=0:2)setDT(w)d <- w[, .(y=rep(y, k[tx, as.character(y)])), by=.(tx, y)]# Define the form of non-PO: special effect for deathg <-function(y) 1* (y ==2)# Second formula given to blrm specifies predictors allowed# to operate in non-POset.seed(11)f <-blrm(y ~ tx, ~ tx, cppo=g, data=d)f```From the output there is a very low probability that $\beta > 0$, i.e., a very high probability that $\beta < 0$, i.e., that treatment B is beneficial.Compute posterior mode odds ratios from this fit and compare to the observed ORs.```{r}h <-function(f) { k <-coef(f, stat='mode') beta <- k['tx=B'] tau <- k['tx=B x f(y)'] or <-c(exp(beta), exp(beta + tau), exp(tau))names(or) =c('B:A overall', 'B:A Y=2', 'Y=2:Y>=1')printL('Posterior mode odds ratios'=or)}h(f)```The Bayesian estimates are virtually the same as the empirical estimates.Now add informative priors. For the overall treatment effect $\beta$ the prior is chosen so that there is only a 0.025 chance of the OR exceeding 4 and a 0.025 chance of being below $\frac{1}{4}$. For the departure from PO, $\tau$ represents the log of the ratio of the OR for death to the OR for the general effect of treatment denoted by $\log(r)$. The prior of $\tau$ is chosen so that there is a 0.9 chance that $r$ is in the interval $[\frac{1}{2}, 2]$. So we are assuming it is unlikely that the treatment effect on death differs from the general effect by more than a factor of 2 in either direction.For the `blrm` function priors are stated in terms of contrasts so that convenient user data units can be used.```{r}. <- list # convenient abbreviation# Contrast for betasigma <-log(4) /qnorm(0.975)pcon <- .(sd=sigma, c1=.(tx='B'), c2=.(tx='A'),contrast=expression(c1 - c2))npcon <- pconnpcon$sd <-log(2) /1.644854f <-blrm(y ~ tx, ~ tx, cppo=g, data=d,pcontrast=pcon, npcontrast=npcon)fh(f)```The parameters are attenuated by the skeptical priors.Compute the probability of an overall effect, a treatment effect on mortality, and the probability that the the differential treatment effect on mortality vs. overall is by more than a factor of 1.2.```{r}# The rmsb function PostF makes it easy to compute posterior probs.# of any assertions (by computing proportion of posterior draws # meeting the conditions)P <-PostF(f, pr=TRUE)printL('Pr(beta < 0)'=P(b1 <0),'Pr(beta + tau < 0)'=P(b1 + b2 <0),'Pr(ratio of ORS > fold change of 1.2)'=P(abs(b2) >log(1.2)), dec=4)```We see strong evidence for an overall treatment benefit, moderate evidence for a mortality reduction, and little evidence for a strong non-PO effect, i.e., ratio of ORs $> 1.2$ or $< \frac{1}{1.2}$. In other words, there is not much evidence for an inconsistent treatment effect. To be fair, there is not much evidence for a consistent treatment effect either, using a cutoff for $r$ of 1.2 or its reciprocal.## Six-level Outcome Example and Frequentist PowerSuppose that in the control group we expect the following proportions of levels of $Y$.```{r}p <-c(.2, .32, .2, .105, .1, 0.075)names(p) <-paste0('Y=', 0:5)p```So the probability of death in treatment A is 0.075. Say we want to detect a common OR of 0.65 with 0.9 power at $\alpha=0.05$ with equal sample sizes in the two groups. The needed sample size for the full ordinal outcome is computed below using the R `Hmisc` package `posamsize` function. [This function needs the average probabilities over the two treatments so we have move the probabilities by the square root of the odds ratio to get the averages and still set up for the target OR in the B:A comparison. The `pomodm` function in `Hmisc` does the needed OR shifting of probabilities.]{.aside} For us to have any hope of detecting a mortality difference, set the binary outcome power to 0.5. ```{r}or <-0.65pmid <-pomodm(p=p, odds.ratio=sqrt(or))pB <-pomodm(p=p, odds.ratio=or)round(rbind(A=p, B=pB, Average=pmid), 3)nord <-round(posamsize(p=pmid, odds.ratio=or, power=0.9)$n)printL('Sample size needed for ordinal Y'= nord)pdeath1 <- p[length(p)]pdeath2 <-plogis(qlogis(pdeath1) +log(or))printL('Probabilities of death for the two treatments'=c(pdeath1, pdeath2), dec=4)nbin <-round(sum(bsamsize(pdeath1, pdeath2, power=0.5)))printL('Sample size needed for binary Y'= nbin)n <-max(nord, nbin)# Check OR for mortalityprintL('OR for mortality:'= (0.05/0.95)/(0.075/0.925), dec=3)```Select as the study sample size the minimum of the sample sizes needed for the ordinal comparison (at 0.9 power) and for the binary comparison (at 0.5 power). The total sample size needed is $n$=`r n`.As a check, compute the power for the standalone mortality comparison using the PO/Wilcoxon test formula.```{r}printL('Binomial test power'=bpower(0.075, odds.ratio=or, n=n), dec=3)pmA <-c(1- p[6], p[6])pmMid <-c(1- pmid[6], pmid[6])printL('Ordinal test power for binary Y'=popower(p=pmMid, odds.ratio=or, n=n))```## More About Bayesian BorrowingThe assumption we'll make is that there is some similarity of treatment effect on $Y=1, \ldots, 4$ as there is on $Y=5$ (death). Similarity will be expressed as how likely it is for the effect on $Y=5$ to be very different than the effect on $Y=1, \ldots, 4$. The similarity of treatment effects is captured by the ratio of two odds ratios---the B:A OR for $Y=5$ and the B:A OR for $Y\geq y$ where $0 < y < 5$ : $\frac{\exp(\beta + \tau)}{\exp(\beta)} = \exp(\tau)$. Let's put a prior on $\tau$, the log ratio of ORs, such that it is equally likely that the ratio falls is below 1 as it is above 1. Use a Gaussian (normal) prior distribution for the log ratio, $\tau$, with mean zero to accomplish this. Then select the standard deviation of the normal distribution to control the amount of borrowing of treatment effect information across $Y$ levels.Let $r$ be the ratio of ORs as before. Skepticism against $r$ being far from 1.0 (closeness to 1.0 indicating a belief that the mortality effect is similar to the other effects) can be specified in many ways. One way is by selecting an interval $[a, b]$ for which one believes there is a chance of 0.9 of $r$ being in that interval. Let's make the tail areas equal so that $\Pr(r < a) = \Pr(r > b) = 0.05$. If $a = \frac{1}{b}$ then $\log(a) = -\log(b)$ and if $\log(r)$ has a normal distribution with mean $\mu$ and standard deviation $\sigma$ then $\mu=0$ in this symmetric case. In general $\mu = \frac{\log(b) + \log(a)}{2}$ and $\sigma=\frac{\log(b) - \log(a)}{2q}$ where $q = \Phi^{-1}(0.95) = 1.645$, the 0.95 quantile of the standard normal distribution.For a variety of $a, b$ here are the corresponding prior distribution mean and standard deviations. All but the last has $a = \frac{1}{b}$ and so has a mean of zero. The last one, $[1, 7]$, gives only a 0.05 chance for the treatment effect on mortality to be better (smaller OR) than the effect on the other outcome levels. ```{r}bv <-c(1.1, 1.25, 1.5, 1.75, 2:7, 7)av <-c(1/ bv[1:10], 1)w <-data.table(a=av, b=bv, mu=(log(bv) +log(av)) /2,sigma=(log(bv) -log(av)) / (2*1.644854))g <-function(x) ifelse(x >=1, x, paste0('1/', 1/x))u <- w[, .(Interval=paste0('[', g(a), ', ', b, ']'),mu=round(mu, 3), sigma)]print(u, digits=3)```Here are the prior distributions for $\log(r)$ for the above $[a, b]$.```{r}#| fig-width: 7#| fig-height: 4.5x <-seq(-3.5, 3.5, length=300)f <-function(mu, sigma) list(x=x, y=dnorm(x, mu, sigma))w <- u[, f(mu, sigma), by=.(mu, sigma, Interval)]br <-sort(log(c(1/c(1,2,3,4,6,9), 2:9)))br2 <-sort(log(c(1/(1:10), 2:10)))ggplot(w, aes(x, y, col=Interval)) +geom_line() +scale_x_continuous(breaks=br, labels=g(exp(br)),minor_breaks = br2) +xlab('Ratio of ORs') +ylab('') ```## Bayesian Power SimulationBayesian power is taken to mean the probability that the posterior probability of a benefit on mortality exceeds 0.95.For a total $n$=`r n` use the `blrm` function to fit the constrained partial PO model with a variety 0.9 intervals for $r$. The intervals are symmetric in $\log(r)$. By simulating 1000 upper $r$ 0.9 interval values we don't need to replicate any one of them in the simulations as we can just interpolate/smooth over the iterations to estimate Bayesian power as a function of the 0.9 interval chosen.The constraint for partial PO will be such that it applies to death ($Y=5$). The prior for the main treatment effect $\beta$ will be left as non-informative, and the prior for the mortality-differential treatment effect $\tau$ is specified through a non-PO contrast (argument `npcontrast` to `blrm`).In this simulation, the data generating mechanism is such that the treatment effect is constant (OR=0.65) across all levels of outcomes. The analysis of a mortality-specific effect does not have access to this information.```{r sim}w <-data.table(b =seq(1.01, 4, length=1000)) # using intervals [1/b, b]w[, sigma :=log(b) /1.644854]# Function to simulate one sample and compute the posterior probability# of treatment benefit on mortalitysim1 <-function(n, pcontrol, or=0.65, sigma) {# n: number of pts in each group# pcontrol: vector of outcome probabilities for control group# or: odds ratio to detect i <<- i +1cat(i, '\n', file='/tmp/z')# Compute outcome probabilities for new treatment ptr <-pomodm(p=pcontrol, odds.ratio=or) k <-length(pcontrol) -1 tx <-c(rep(0, n), rep(1, n)) y <-c(sample(0: k, n, replace=TRUE, prob=pcontrol),sample(0: k, n, replace=TRUE, prob=ptr) )# Set prior on the "treatment by Y interaction" contrast npcon <-list(sd=sigma, c1=list(tx=1), c2=list(tx=0),contrast=expression(c1 - c2)) f <-blrm(y ~ tx, y ~ tx, cppo=function(y) y ==5,npcontrast=npcon,loo=FALSE, method='sampling', iter=1000) beta <- f$draws[, 'tx'] tau <- f$draws[, 'tx x f(y)']list(p1=mean(beta <0), p2=mean(beta + tau <0), p3=mean(abs(tau) >0.2))}g <-function() {set.seed(7) R <-copy(w) R[, sim1(round(n /2), p, sigma=sigma), by=.(sigma, b)]}i <-0R <-runifChanged(g, w, n, file='sim.rds')```Look at the distribution of the three posterior probabilities.```{r}u <-meltData(p1 + p2 + p3 ~ b, tall='left', data=R)lb <-c(p1='beta < 0', p2='beta + tau < 0', p3='abs(tau) > 0.2')u[, variable := lb[variable]]cnt <-c(1:5, 10, 25, 50)ggplot(u, aes(x=b, y=value)) +stat_binhex(aes(fill=cut2(after_stat(count), cnt)), bins=75) +facet_wrap(~ variable, nrow=3, label='label_parsed') +guides(fill=guide_legend(title='Frequency')) +xlab('0.9 Interval Upper Limit b') +ylab('Posterior Probability')```Show Bayesian power vs. $b$, which summarizes the amount of endpoint borrowing. Powers of three assessments are shown:* treatment effect on ordinal outcome: $\beta < 0$ (top curves)* treatment effect on mortality: $\beta + \tau < 0$ (middle curves)* strength of non-PO: $|\tau| > 0.2$ (bottom curves)Use binary logistic regression and overlapping moving window proportions to interpolate/smooth the results.```{r}v <- u[, hit :=1* (value >0.95), by=.(variable, b)]IT <-0m <-movStats(hit ~ b + variable,eps=100, lrm=TRUE, lrm_args=list(maxit=30),nignore=0, data=v, melt=TRUE)ggplot(m,aes(x=b, y=hit, col=variable, linetype=Type)) +geom_line() +geom_hline(yintercept=0.8, alpha=0.3) +scale_x_continuous(breaks=seq(1, 7, by=1),minor_breaks=seq(1, 7, by=.25)) +scale_y_continuous(breaks=seq(0, 1, by=0.1),minor_breaks=seq(0, 1, by=0.05)) +scale_colour_discrete(labels = scales::parse_format()) +guides(color=guide_legend(title='')) +ylab('Bayesian Power')# Find b such that power is 0.8b8 <- m[variable=='beta + tau < 0'& Type=='LR',approx(hit, b, xout=0.8)$y]b8 <-round(c(1/ b8, b8), 3)printL('0.9 Interval for r yielding 0.8 power for mortality assessment'= b8)```The posterior probability that $|\tau| > 0.2$ hovered around zero, which is good since data were generated assuming PO. Bayesian power for the overall treatment effect is nearly 1.0. The minimum value of $b$ required to achieve 0.8 Bayesian power is `r b8[2]`.## What Constraints Does a Partial PO Model Place on $Y$-specific Treatment Effects?Consider a 4-level dependent variable $Y=0,1,2,3$, a 2-level baseline covariate $Z=0, 1$, and a 2-level treatment $X=0,1$. Assume a partial proportional odds (PPO) model$$P(Y \geq y | X, Z) = \text{expit}(\alpha_{y} + \beta X + \gamma Z + \tau_{1} X[y=2] + \tau_{2} X[y=3])$$Make $P(Y \geq y | X=0, Z=0) = 0.3, 0.2, 0.1$ when $y=1, 2, 3$, allowing solving for $\alpha$.```{r}require(ggplot2)require(data.table)alpha <-qlogis(c(0.3, 0.2, 0.1))alpha```Let Z, for which PO is assumed, have an odds ratio (OR) of $\frac{0.4/0.6}{0.3/0.7} = \exp(\gamma)$ so that $P(Y \geq 1 | X=0, Z=1) = 0.4 = \text{expit}(\alpha_{1} + \gamma)$.```{r}gamma <-log((0.4/0.6) / (0.3/0.7))gamma```Let the $X=1:0$ OR for $Y\geq 1$ be 0.7 so that $\beta = \log(0.7)$. Now the only free parameters are the non-PO parameters $\tau_{1}, \tau_{2}$.```{r}beta <-log(0.7)beta```Vary $\tau$ over a regular grid and plot the resulting differences in probabilities corresponding to $y=1, 2, 3$, separately for each $Z$. These differences are absolute risk reductions (ARR) due to treatment ($X=1$), with ARR=0 corresponding to OR=1.It is important to note that for all the cell probabilities (differences in consecutive cumulative probabilities) to be legal, i.e., in $[0,1]$, it is necessary that the intercepts in effect be in descending order. The intercepts in effect are the within-$y$ sums of all terms that change with $y$. This includes the main $\alpha$ intercepts and applicable $\tau$s. $\tau$ is applicable only when $X=1$, so consider the $X=1$ case where the model is$$P(Y \geq y | X, Z) = \text{expit}(\alpha_{y} + \beta + \tau_{1} [y=2] + \tau_{2} [y=3])$$when the ignorable $Z$ is zero. The intercepts in effect when $y=1, 2, 3$, respectively, are $\alpha_{1}$, $\alpha_{2} + \tau_{1}$ and $\alpha_{3} + \tau_{2}$. So the requirement is$$\alpha_{1} > \alpha_{2} + \tau_{1} > \alpha_{3} + \tau_{2}$$```{r}expit <- plogisd <-expand.grid(tau1 =seq(-5, 4, by=0.05),tau2 =seq(-5, 4, by=0.05),Z =0:1,y =1:3)setDT(d)d <- d[alpha[1] > alpha[2] + tau1 & alpha[2] + tau1 > alpha[3] + tau2, ]# d <- d[between(alpha[2] + tau1, alpha[3] + tau2, alpha[1], incbounds=FALSE), ]d[, p1 :=expit(alpha[y] + gamma * Z)]d[, p2 :=expit(alpha[y] + beta + gamma * Z + (y ==2) * tau1 + (y ==3) * tau2)]d[, ARR := p1 - p2]d[, OR :=exp(beta + (y ==2) * tau1 + (y ==3) * tau2)]g <-function(x) { r <-round(range(x, na.rm=TRUE), 3)c(min=r[1], max=r[2])}d[, rbind('Overall ARR'=g(ARR),'y=1'=g(ARR[y ==1]),'y=2'=g(ARR[y ==2]),'y=3'=g(ARR[y ==3]),'y=3, tau1=0'=g(ARR[y ==3& tau1 ==0]))]ggplot(d, aes(x=tau1, y=tau2, color=ARR)) +geom_point() +geom_vline(xintercept=0, col='red') +facet_grid(y ~ Z) +xlab(expression(tau[1])) +ylab(expression(tau[2]))```Little restriction is placed on the treatment effect on $Y=3$ when a special treatment effect is also allowed for $Y=2$ (ARR ranges over $[-0.16, 0.145]$). Now restrict attention to the special case of not allowing a special non-PO treatment effect on $Y=2$, i.e., when $\tau_{1}=0$ which is along the vertical lines in the graph. As makes sense, ARR does not vary with $\tau_{2}$ when considering ARR for $Y\geq 1$ and for $Y \geq 2$. For $Y \geq 3$ (the bottow row of the graph), there remains a range of ARR from -0.065 to 0.145. A constrained partial PO model with only a special effect of $X$ when $y=3$ allows the treatment to be completely ineffective on death in this example, and allows for up to a 0.065 increase in mortality risk.Note that ARR is restricted to be $\leq 0.275$ since the base risks are $< 0.5$. This restriction is essentially the restriction of having non-negative $P(Y \geq y)$.Now consider the different ORs allowed in the partial PO models.```{r}d[, rbind('Overall OR'=g(OR),'y=1'=g(OR[y ==1]),'y=2'=g(OR[y ==2]),'y=3'=g(OR[y ==3]),'y=3, tau1=0'=g(OR[y ==3& tau1 ==0]))]ggplot(d, aes(x=tau1, y=tau2, color=OR)) +geom_point() +geom_vline(xintercept=0, col='red') +facet_wrap(~ y) +xlab(expression(tau[1])) +ylab(expression(tau[2]))```The is virtually no limit on how small OR can be when $\tau_{1}=0$. Concerning treatment worsening the chance of $Y=3$, by only allowing a special treatment effect for $y=3$ the upper limit of allowed OR is 1.56.::: {.callout-note collapse="true"}## A Note About Time To EventOur example considers death as a binary event. Analyzing it instead as time-to-event in its own model will allow for variable follow-up time and will increase power if deaths are common. If the incidence of death is low as in our simulation design, little power is gained from utilizing event times.A [Markov longitudinal ordinal model](https://hbiostat.org/rmsc/markov) can jointly analyze ordinal responses as well as time to event while allowing for variable follow-up.:::## SummaryThe partial proportional odds model provides a formal way to quantify evidence for a treatment effect on a given interval of an ordinal outcome. When one of the outcomes is very important but relatively rare, it is difficult to size studies to have power to show a treatment effect on that outcome without borrowing some information from the treatment effect on the outcomes that have a higher effective sample size. The question is how much borrowing is clinically acceptable. The above simulation example shows how much borrowing is required for power for a treatment comparison on the highest outcome level to be adequate. Researchers can run similar simulations for their situations, and judge whether the amount of borrowing needed for adequate Bayesian power is justifiable. In the simulation, the required amount of borrowing to achieve at least 0.8 Bayesian power for mortality assessment involves assuming that the differential treatment effect on mortality (ratio of two odds ratios) is in the interval $[`r b8[1]`,`r b8[2]`]$ with 0.9 probability, or is in a narrower interval.A separate simulation was done using $\frac{1}{2}$ the sample size. The amount of borrowing needed to achieve 0.8 Bayesian power for a mortality assessment was $b=1.3$. A good rule of thumb may be to expect to need a power of a standalone mortality assessment to be at least 0.5 for the Bayesian power to be sufficient with a reasonable amount of borrowing. When a study doesn't have a good chance of demonstrating a mortality difference with little or no borrowing of information across levels of $Y$, it may be important to clinically pre-specify the prior for the inconsistency of mortality and non-fatal effects before the study, and to stick with that for computing the posterior probability of a mortality benefit.It is important to note that because the PO model [is always consistent](https://fharrell.com/post/powilcoxon) with a Wilcoxon test in terms of the direction of a treatment effect (and whether the effect is zero), the more powerful PO model that does not include the partial PO parameter for a special effect of treatment on mortality will have strong ability to discern which treatment is better overall, penalizing for death, if there is clinical consensus on the outcome rankings. This is despite the problem caused by strong violation of PO for the treatment variable: the PO model may give the wrong assessment of the isolated effect of treatment on mortality.